In this day and age it’s generally not a good idea to train a Deep Neural Network (DNN) from scratch without first trying to find an existing neural network that accomplishes a similar task to the one you are trying to tackle.
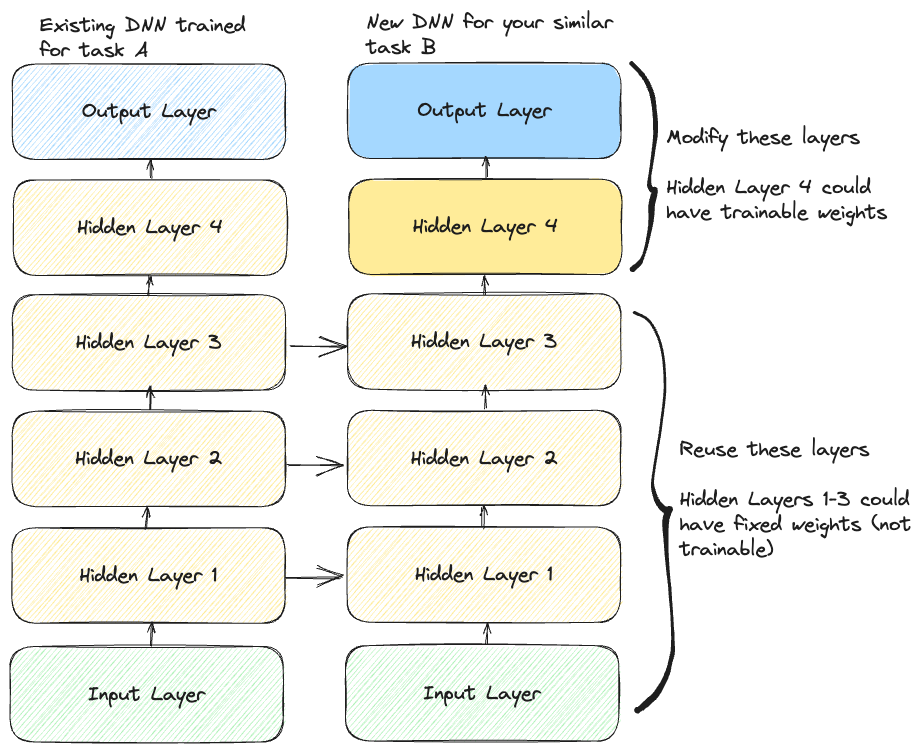
Typically in such cases it’s common to re-use most of the network layers (except for the top ones). This act if more formally known as Transfer Learning and will not only reduce cost of compute but also training time (amongst other things).
Example: Imagine you have the task of classifying a bunch of images into various different categories. Instead of training a DNN from scratch you can search the web for an existing model trained on a similar task (HuggingFace image classification models, TensorFlow Hub image classification model etc), download and read the model into memory and then adapt the model alittle to your task.
Note: When doing this if the input data doesn’t have the same size as that required by the original model architecture you may need a pre-processing step to reshape your data to the right size. More generally, transfer learning will work best when the inputs have similar low-level features.
Interesting points to bear in mind
- The output layers of the original model should be replaced because it’s most likely not useful for the given task.
- Since usually you woudn’t find an exact model tailored to your task1. This is intuitive since the good pre-trained models are usually foundational and thus were trained on large datasets with lots of classes.
- Going back to our example if you only want to classify images for 2 categories yet the pre-trained model you are using may have had 100’s of categories.
- The upper hidden layers of the original model are less likely to be useful compared to the lower layers.
- Since the base level features are typically thought to be learn’t in the earlier layers and the high level features in the layers above. These high level features are less likely to be useful for your current task as you can think of it as being “too granular and overfit” to the original models data.
- The more similar the tasks are the more layers you’d want to reuse
- Starting with lower layers and working up to higher layers.
- For very similar tasks try to keep all hidden layers the same and just replace output layer if necessary.
- Finding the optimal numbers of layers to remove or reuse can be a relatively iterative process
- First try freezing all reused layers (making weights non-trainable so that they are not updated during gradient descent). Train and evaluate the model and noting down performance.
- Then try unfreezing some of a few (1/2) of the higher layers and allow them to be updated during training and again note down performance alongside training time etc.
- Keep performing the activity if you notice performance improvements and or you have time to experiment. Eventually you’ll land on an ideal number of layers to re-use for your problem.
- In general the more training data you have the more you have room to re-train larger number of layers.
- Also ensure that the learning rate isn’t too high when unfreezing multiple layers to avoid wrecking the weights of the fine-tuned layers.
What does code for this look like?
Below is some basic pseudo-code using the TensorFlow and Keras framework on how you could load a model, fiddle around with its weights and then train it on some data.
import tensorflow as tf
# Assuming some original_model has already been trained and saved we can load it in directly
# Cloning the model to ensure original model isn't overwritten
original_model = tf.keras.models.load_model("original_model")
original_model_clone = tf.keras.models.clone_model(original_model)
original_model_clone.set_weights(original_model.get_weights())
# Instatiating new model same as original model except without final layer
# Sigmoid activation used assuming some binary classification task
new_model = tf.keras.Sequential(original_model_clone[:-1])
new_model.add(tf.keras.layers.Dense(1, activation=sigmoid))
# Looping through all the reused layers of the network and freezing them using the trainable attribute
# This enables the new output layer to adjust it's weights from default intialization without getting wrecked
for layer in new_model.layers[:-1]:
layer.trainable = False
# Compiling and optimizing your model, additional metrics can be set at your discretion
optimizer = tf.keras.optimizers.SGD(learning_rate=0.001)
new_model.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=[<add_additional_metrics>])
new_model.fit(X_train, y_train, epochs=<some_small_number>, validation_data=(X_valid, y_valid))
# Unfreezing the reused layers since the output layer should have "warmed up" by now
for layer in new_model.layers[:-1]:
layer.trainable = True
# Compiling model again since we froze and then unfroze our layers (mandatory)
# Reducing the learning rate to avoid damaging the reused weights
optimizer = tf.keras.optimizers.SGD(learning_rate=0.0001)
new_model.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=[<add_additional_metrics>])
# Finishing training for however many epochs
new_model.fit(X_train, y_train, epochs=<some_larger_number>, validation_data=(X_valid, y_valid))
# Evaluating on your holdout dataset
model.evaluate(X_test, y_test)
In general you could imagine making this workflow more modular and being able to repeat the iterative process described above to test how many layers are worth reusing.
-
There is a chance you find a perfect model so be sure to check various resources before choosing one. Some additional sites are Papers with Code and Kaggle Models ↩