Intro
Ever tried baking a cake and realized you didn’t mix the batter evenly? One bite is sugary heaven, and the next… not so much. That’s what happens when your sample of ingredients isn’t representative of your population. Enter stratified sampling—the trusty whisk that ensures every slice of your data cake is just right!
What is Stratified Sampling?
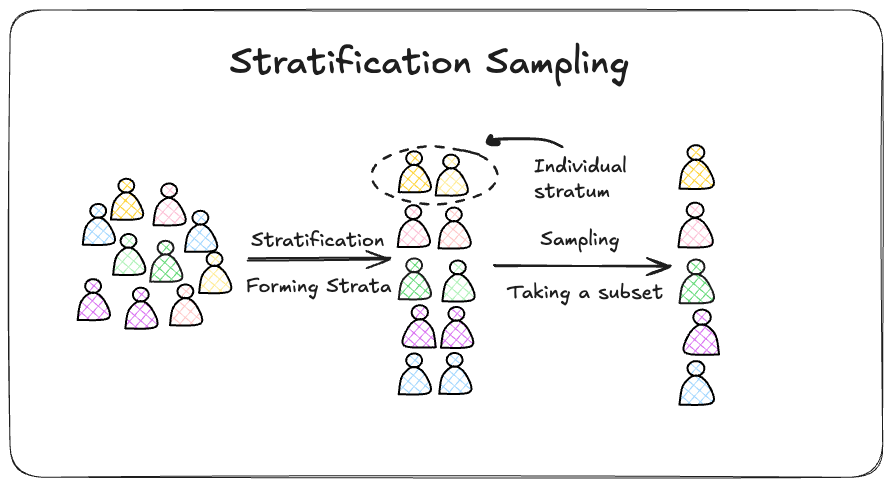
Imagine your dataset is like a layered parfait. You’ve got distinct groups/attributes, or “strata”, that make up the whole—maybe it’s age groups, income levels, or favorite pizza toppings. Instead of scooping out a random chunk of parfait and hoping for the best, stratified sampling makes sure you get a taste of every layer.
In technical terms, stratified sampling divides your population/ dataset into non-overlapping groups (strata) based on a shared characteristic. The characteristics or attributes you choose to define a single strata is upto you; You’d just want to make sure your choice captures all the features of interst i.e “layers of your parfeit”. Then, you take samples from each group, either in equal proportions or in line with their size in the population. Voilà! You’ve got a sample that mirrors your population, layer by layer.
Use in ML to get a representative training dataset
When it comes to training data it’s common to encounter a dataset too large to work with efficiently. Processing such large datasets can be time-consuming and computationally expensive. This is where stratified sampling comes to the rescue. By using stratified sampling, you can create a smaller, yet representative, sample of your dataset that maintains the distribution of key attributes.
Imagine you have a customer dataset with millions of entries, and you want to predict whether a customer will churn or not. Often, such datasets have an imbalanced classification target variable, where the number of customers who churn is much smaller than those who do not. Instead of randomly selecting a few thousand entries and risking an unbalanced sample, stratified sampling ensures that each class (churn and no churn) is proportionally represented. This way, your smaller sample still reflects the diversity and structure of the original dataset.
For example, if 10% of your customers churn and 90% do not, stratified sampling will ensure that your sample maintains this 10:90 ratio. This leads to more accurate and reliable training results, as your model learns from a dataset that truly mirrors the population.
Here is some BigQuery code to do the job, this can be adapted if you’re using a different flavour of SQL & database storage engine.
DECLARE desired_sample_size INT64 DEFAULT 200000;
CREATE OR REPLACE TABLE
`<project_id>.<dataset_name>.<sample_table_name>`
AS
WITH population AS (
SELECT
*,
COUNT(*) OVER () AS total_population
FROM
`<project_id>.<dataset_name>.<source_data_table_name>`
),
strata AS (
SELECT
*,
COUNT(*) OVER (PARTITION BY target) AS stratum_count
FROM
population
),
sample_size AS (
SELECT
*,
CAST(ROUND(stratum_count / total_population * desired_sample_size) AS INT64) AS samples_per_stratum
FROM
strata
),
ordered AS (
SELECT
*,
ROW_NUMBER() OVER (
PARTITION BY <target_field_name>
ORDER BY FARM_FINGERPRINT(CAST(<customer_level_id> AS STRING))
) AS ranking
FROM
sample_size
)
SELECT
*
EXCEPT(total_population, stratum_count, samples_per_stratum, ranking)
FROM
ordered
WHERE
ranking <= samples_per_stratum;
We use the FARM_FINGERPRINT function to ensure deterministic sampling, allowing us to consistently reproduce the same results. By hashing and ordering the data, we can reliably sample from defined strata. The number of samples per stratum will not exceed the stratum count, provided the sample size is smaller than the total population.
The other convienence is being able to select the final sample size we want, common algorithms such as XGBoost saturate their performance at several 100,000 records but worthwhile tinkering to your liking.
Conclusion
In summary, stratified sampling allows you to work with large datasets more efficiently by enabling you to use a smaller, yet representative, sample. This not only saves time and computational resources but also helps in building more robust and generalizable machine learning models, especially when dealing with imbalanced classification problems.