Table of Contents
- Importing libraries and setting up variables
- Defining wrappers for VertexAI
- Setting up models
- Configuring BigQuery
- Creating SQL agent
- Conclusion
Note: Much of the functionality in this post has been inspired by stuff seen in the GCP - GenAI language repo, can check it out here
When it comes to Langchain one of it’s coolest perks is ease of compatability with various different sources. It’s nature makes it easy to switch various components out and customise those components to your specific needs.
In this short post I’ll provide a brief walkthrough of using Langchain to create your own LLM based SQL agent to answer your data questions relating to a table, something I kind of touched on in my other post.
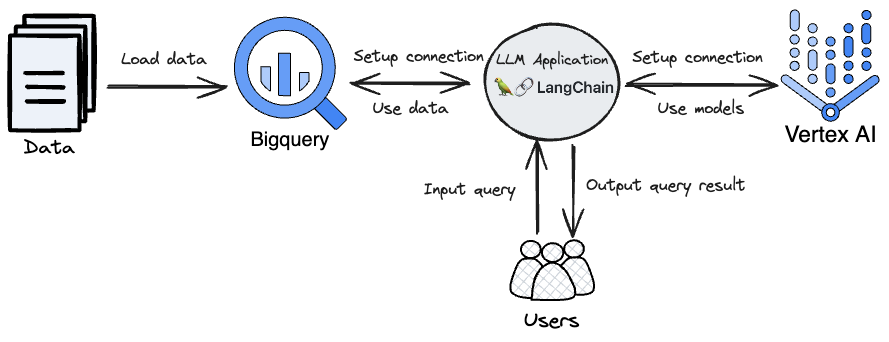
While some may enjoy writting SQL for alot it’s just a “means to an end” and a necessary tool for accessing the data we want. With this capability you can pose your desired data in the form of natural language input and get natural language back summarising your result.
Ok lets get started….
Importing libraries and setting up variables
When working with GCP you need to setup your “project” which typically represents the highest identifier level for your project, this is useful as any resources you create as part of your project will be tied under this id, meaning things like resource management and billing become easier. For more info checkout their docs
Also when using resources in the cloud your ultimately just renting hardward that Google owns and is distributed across their various datacenters. As a result you can specify the region you want to run your services from to ensure you’re using the optimally located resources for you sceanrio. For more insights checkout their docs
As such it’s worth defining some key variables project wide
from dataclasses import dataclass
@dataclass
class ProjectSetup():
# GCP wide settings
PROJECT_ID : str = <take_your_id_from_google_cloud_console>
LOCATION : str = <take_your_region_from_google_cloud_console>
# Bigquery settings
DATASET_ID : str = <your_dataset_name>
TABLE_NAME : str = <your_dataset_table_name>
SOURCE_TABLE : str = <full_bq_table_schema_name>
# Model settings
REQUESTS_PER_MINUTE : int = 100
cfg = ProjectSetup()
Now when setting up your virtual environment amongst other things you need to make sure you install Langchain (pip install langchain) and Googles AI SDK (pip install google-cloud-aiplatform).
Here is more comprehensive list with version numbers as required:
pip install langchain==0.0.229
pip install pydantic==1.10.8
pip install typing-inspect==0.8.0
pip install sqlalchemy-bigquery
pip install SQLAlchemy==1.4.48
pip install google-cloud-aiplatform==1.25.0
pip install google-cloud-bigquery
Then adding our import statements would look like
# Standard python imports
import time
from typing import Any, Mapping, List, Dict, Optional, Tuple, Union
from dataclasses import dataclass, field
# Pydantic imports
from pydantic import BaseModel, Extra, root_validator
# SQL alchemy imports
from sqlalchemy.engine import create_engine
from sqlalchemy import schema
# GCP imports
from google.cloud import aiplatform
from google.cloud import bigquery
from google.cloud.bigquery import Client
import vertexai
vertexai.init(project=cfg.PROJECT_ID, location=cfg.LOCATION)
from vertexai.preview.language_models import TextGenerationResponse, ChatSession
# Langchain imports
import langchain
print(f"LangChain version: {langchain.__version__}")
from langchain.llms.base import LLM
from langchain.embeddings.base import Embeddings
from langchain.chat_models.base import BaseChatModel
from langchain.llms.utils import enforce_stop_tokens
from langchain.schema import Generation, LLMResult
from langchain.schema import AIMessage, BaseMessage, ChatGeneration, ChatResult, HumanMessage, SystemMessage
from langchain import SQLDatabase, SQLDatabaseChain
from langchain.prompts.prompt import PromptTemplate
A quick note on some of the other stuff
pydantic- This library is great for data validation and leverages python’s type hinting abilities to automatically check objects, returning errors.
- This can help ensure your application is handling things correctly.
- Checkout docs for more!
typing- This standard library is great for allowing type hinting for various python objects.
- Checkout docs for more!
dataclasses- Provides useful ways of instantiating a class (e.g automatic
__init__and__repr__methods). - Can help turn classes into an easy to use config object.
- Provides useful ways of instantiating a class (e.g automatic
- Low level
Langchain- A bunch of the custom wrapper functions in the following section inherit from the base langchain classes to aid compatability.
SQLAlchemy
Defining wrappers for VertexAI
I came across the following notebooks (notebook 1, notebook 2) which provide some useful wrapper functionality when working with VertexAI LLM models.
The point of these wrappers is ultimately to add some additional functionality to the base Vertex model APIs that are available to enable a slightly smoother end user experience (encapsulating certain complexities). Beyond that they are not 100% compulsory and you could create the functionality yourself
We’ll touch on them as they are defined.
API request rate limit
One slightly non-trivial thing is that when working with these APIs it costs money to have to ping it really frequently. As a result we can create some functionality which limits that amount we can be charged based some predefined limit.
Remember the key behind this functionality is that the underlying API you’re limiting is something that is being used frequently and so you want to stager the use of those APIs.
def rate_limit(max_per_minute):
# Minimum time period in seconds for each API call based on your specified max
period = 60 / max_per_minute
print('Waiting')
while True:
before = time.time()
yield
after = time.time()
elapsed = after - before
sleep_time = max(0, period - elapsed)
if sleep_time > 0:
print('.', end='')
time.sleep(sleep_time)
The above function makes use of generators and essentially “freezes” further executions of the API calls if they are coming in faster than the specified limits provided. The process sleeps until the period sleep_time has elapsed allowing for the specified API limits to be maintained.
Base functionality
Here we can define the classes which will be inherited by a bunch of the other classes we create.
class _VertexCommon(BaseModel):
"""Wrapper around Vertex AI large language models.
To use, you should have the
``google.cloud.aiplatform.private_preview.language_models`` python package
installed.
"""
client: Any = None #: :meta private:
model_name: str = "text-bison@001"
"""Model name to use."""
temperature: float = 0.2
"""What sampling temperature to use."""
top_p: int = 0.8
"""Total probability mass of tokens to consider at each step."""
top_k: int = 40
"""The number of highest probability tokens to keep for top-k filtering."""
max_output_tokens: int = 200
"""The maximum number of tokens to generate in the completion."""
@property
def _default_params(self) -> Mapping[str, Any]:
"""Get the default parameters for calling Vertex AI API."""
return {
"temperature": self.temperature,
"top_p": self.top_p,
"top_k": self.top_k,
"max_output_tokens": self.max_output_tokens
}
def _predict(self, prompt: str, stop: Optional[List[str]]) -> str:
res = self.client.predict(prompt, **self._default_params)
return self._enforce_stop_words(res.text, stop)
def _enforce_stop_words(self, text: str, stop: Optional[List[str]]) -> str:
if stop:
return enforce_stop_tokens(text, stop)
return text
@property
def _llm_type(self) -> str:
"""Return type of llm."""
return "vertex_ai"
@dataclass
class _MessagePair:
"""InputOutputTextPair represents a pair of input and output texts."""
question: HumanMessage
answer: AIMessage
@dataclass
class _ChatHistory:
"""InputOutputTextPair represents a pair of input and output texts."""
history: List[_MessagePair] = field(default_factory=list)
system_message: Optional[SystemMessage] = None
def _parse_chat_history(history: List[BaseMessage]) -> _ChatHistory:
"""Parses a sequence of messages into history.
A sequency should be either (SystemMessage, HumanMessage, AIMessage,
HumanMessage, AIMessage, ...) or (HumanMessage, AIMessage, HumanMessage,
AIMessage, ...).
"""
if not history:
return _ChatHistory()
first_message = history[0]
system_message = first_message if isinstance(first_message, SystemMessage) else None
chat_history = _ChatHistory(system_message=system_message)
messages_left = history[1:] if system_message else history
# if len(messages_left) % 2 != 0:
# raise ValueError(
# f"Amount of messages in history should be even, got {len(messages_left)}!"
# )
for question, answer in zip(messages_left[::2], messages_left[1::2]):
if not isinstance(question, HumanMessage) or not isinstance(answer, AIMessage):
raise ValueError(
"A human message should follow a bot one, "
f"got {question.type}, {answer.type}."
)
chat_history.history.append(_MessagePair(question=question, answer=answer))
return chat_history
VertexAI Text model
This is the main class which instantiates the model that we will use in this post. You can read more about the model itself here.
class VertexLLM(_VertexCommon, LLM):
model_name: str = "text-bison@001"
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""Validate that the python package exists in environment."""
try:
from vertexai.preview.language_models import TextGenerationModel
except ImportError:
raise ValueError(
"Could not import Vertex AI LLM python package. "
)
try:
values["client"] = TextGenerationModel.from_pretrained(values["model_name"])
except AttributeError:
raise ValueError(
"Could not set Vertex Text Model client."
)
return values
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
"""Call out to Vertex AI's create endpoint.
Args:
prompt: The prompt to pass into the model.
Returns:
The string generated by the model.
"""
return self._predict(prompt, stop)
VertexAI Chat model
class _VertexChatCommon(_VertexCommon):
"""Wrapper around Vertex AI Chat large language models.
To use, you should have the
``vertexai.preview.language_models`` python package
installed.
"""
model_name: str = "chat-bison@001"
"""Model name to use."""
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""Validate that the python package exists in environment."""
try:
from vertexai.preview.language_models import ChatModel
except ImportError:
raise ValueError(
"Could not import Vertex AI LLM python package. "
)
try:
values["client"] = ChatModel.from_pretrained(values["model_name"])
except AttributeError:
raise ValueError(
"Could not set Vertex Text Model client."
)
return values
def _response_to_chat_results(
self, response: TextGenerationResponse, stop: Optional[List[str]]
) -> ChatResult:
text = self._enforce_stop_words(response.text, stop)
return ChatResult(generations=[ChatGeneration(message=AIMessage(content=text))])
class VertexChat(_VertexChatCommon, BaseChatModel):
"""Wrapper around Vertex AI large language models.
To use, you should have the
``vertexai.preview.language_models`` python package
installed.
"""
model_name: str = "chat-bison@001"
chat: Any = None #: :meta private:
def send_message(
self, message: Union[HumanMessage, str], stop: Optional[List[str]] = None
) -> ChatResult:
text = message.content if isinstance(message, BaseMessage) else message
response = self.chat.send_message(text)
text = self._enforce_stop_words(response.text, stop)
return ChatResult(generations=[ChatGeneration(message=AIMessage(content=text))])
def _generate(
self, messages: List[BaseMessage], stop: Optional[List[str]] = None
) -> ChatResult:
if not messages:
raise ValueError(
"You should provide at least one message to start the chat!"
)
question = messages[-1]
if not isinstance(question, HumanMessage):
raise ValueError(
f"Last message in the list should be from human, got {question.type}."
)
self.start_chat(messages[:-1])
return self.send_message(question)
def start_chat(self, messages: List[BaseMessage]) -> None:
"""Starts a chat."""
history = _parse_chat_history(messages)
context = history.system_message.content if history.system_message else None
self.chat = self.client.start_chat(context=context, **self._default_params)
for pair in history.history:
self.chat._history.append((pair.question.content, pair.answer.content))
def clear_chat(self) -> None:
self.chat = None
@property
def history(self) -> List[BaseMessage]:
"""Chat history."""
history: List[BaseMessage] = []
if self.chat:
for question, answer in self.chat._history:
history.append(HumanMessage(content=question))
history.append(AIMessage(content=answer))
return history
async def _agenerate(
self, messages: List[BaseMessage], stop: Optional[List[str]] = None
) -> ChatResult:
raise NotImplementedError(
"""Vertex AI doesn't support async requests at the moment."""
)
class VertexMultiTurnChat(_VertexChatCommon, BaseChatModel):
"""Wrapper around Vertex AI large language models."""
model_name: str = "chat-bison@001"
chat: Optional[ChatSession] = None
def clear_chat(self) -> None:
self.chat = None
def start_chat(self, message: Optional[SystemMessage] = None) -> None:
if self.chat:
raise ValueError("Chat has already been started. Please, clear it first.")
if message and not isinstance(message, SystemMessage):
raise ValueError("Context should be a system message")
context = message.content if message else None
self.chat = self.client.start_chat(context=context, **self._default_params)
@property
def history(self) -> List[Tuple[str]]:
"""Chat history."""
if self.chat:
return self.chat._history
return []
def _generate(
self, messages: List[BaseMessage], stop: Optional[List[str]] = None
) -> ChatResult:
if len(messages) != 1:
raise ValueError(
"You should send exactly one message to the chat each turn."
)
if not self.chat:
raise ValueError("You should start_chat first!")
response = self.chat.send_message(messages[0].content)
return self._response_to_chat_results(response, stop=stop)
async def _agenerate(
self, messages: List[BaseMessage], stop: Optional[List[str]] = None
) -> ChatResult:
raise NotImplementedError(
"""Vertex AI doesn't support async requests at the moment."""
)
VertexAI Embedding model
class VertexEmbeddings(Embeddings, BaseModel):
"""Wrapper around Vertex AI large language models embeddings API.
To use, you should have the
``google.cloud.aiplatform.private_preview.language_models`` python package
installed.
"""
model_name: str = "textembedding-gecko@001"
"""Model name to use."""
model: Any
requests_per_minute: int = 15
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""Validate that the python package exists in environment."""
try:
from vertexai.preview.language_models import TextEmbeddingModel
except ImportError:
raise ValueError(
"Could not import Vertex AI LLM python package. "
)
try:
values["model"] = TextEmbeddingModel
except AttributeError:
raise ValueError(
"Could not set Vertex Text Model client."
)
return values
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""Call Vertex LLM embedding endpoint for embedding docs
Args:
texts: The list of texts to embed.
Returns:
List of embeddings, one for each text.
"""
self.model = self.model.from_pretrained(self.model_name)
limiter = rate_limit(self.requests_per_minute)
results = []
docs = list(texts)
while docs:
# Working in batches of 2 because the API apparently won't let
# us send more than 2 documents per request to get embeddings.
head, docs = docs[:2], docs[2:]
# print(f'Sending embedding request for: {head!r}')
chunk = self.model.get_embeddings(head)
results.extend(chunk)
next(limiter)
return [r.values for r in results]
def embed_query(self, text: str) -> List[float]:
"""Call Vertex LLM embedding endpoint for embedding query text.
Args:
text: The text to embed.
Returns:
Embedding for the text.
"""
single_result = self.embed_documents([text])
return single_result[0]
Setting up models
Now with all the model classes defined we can instantiate them to form our various models. For demonstration we have instantiated all of the ones we created classes for however we will only be using the vertex_text_model for our agent.
vertex_text_model = VertexLLM(
model_name='text-bison@001',
max_output_tokens=1024,
temperature=0.1,
top_p=0.8,
top_k=40,
verbose=True,
)
vertex_chat_model = VertexChat()
vertex_mchat_model = VertexMultiTurnChat(max_output_tokens=1024)
vertex_embedding_model = VertexEmbeddings(requests_per_minute=cfg.REQUESTS_PER_MINUTE)
Some nice information is provided here on the meaning behind some of the models parameters.
Configuring BigQuery
Setting up data
On the assumption you have data in BigQuery already then you don’t really need to worry about this section (instead can just take a look to ensure it looks alright and you are comfortable with navigating to it).
client = Client(project=cfg.PROJECT_ID)
create_dataset_query = """
CREATE SCHEMA `{PROJECT_ID}.{dataset_id}`
OPTIONS(
location="us"
)
""".format(
PROJECT_ID=PROJECT_ID, dataset_id=DATASET_ID
)
create_dataset_job = client.query(create_dataset_query)
print(create_dataset_job.result())
create_table_query = """
CREATE OR REPLACE TABLE `{PROJECT_ID}.{DATASET_ID}.{TABLE_NAME}`
AS
(
SELECT
*
FROM {SOURCE_TABLE}
)
""".format(
PROJECT_ID=cfg.PROJECT_ID,
DATASET_ID=cfg.DATASET_ID,
TABLE_NAME=cfg.TABLE_NAME,
SOURCE_TABLE=cfg.SOURCE_TABLE
)
create_table_job = client.query(create_table_query)
print(create_table_job.result())
Creating SQL engine
# Create engine
table_uri = f"bigquery://{cfg.PROJECT_ID}/{cfg.DATASET_ID}"
engine = create_engine(table_uri)
# Test engine by getting first record from query results
query = f"""SELECT * FROM {cfg.PROJECT_ID}.{cfg.DATASET_ID}.{cfg.TABLE_NAME}"""
engine.execute(query).first()
Creating SQL agent
Everything is now ready to be put together, we can create a final function which does the following:
- Creates our database connection
- Utilises our SQL engine defined earlier.
- Packages our connection with our LLM into a SQLchain component
- Purposefully return intermediate steps to make things more transparent.
- Use PromptTemplate functionality to construct our data question with necessary context
- Allows the model to perform better (can think of it as a form of instruction tuning).
- Pass our final prompt to our model
- Can return what we want.
def llm_bq_sql_agent(data_question, engine, table_name):
# Create SQLDatabase instance using our BQ engine
db = SQLDatabase(engine=engine,metadata=MetaData(bind=engine),include_tables=[table_name])
# Create SQLDBChain with the initialized LLM and above SQLDB instance
llm_db_chain = SQLDatabaseChain.from_llm(vertex_text_model, db, verbose=True, return_intermediate_steps=True)
# Define our context for the model
_googlesql_prompt = """You are a BigQuery SQL expert. Given an input question, first create a syntactically correct BigQuery query to run, then look at the results of the query and return the answer to the input question.
Unless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} results using the LIMIT clause as per BigQuery SQL. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in backticks (`) to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist and don't insert into existing tables. Also, pay attention to which column is in which table.
Use the following format:
Question: "Question here"
SQLQuery: "SQL Query to run"
SQLResult: "Result of the SQLQuery"
Answer: "Final answer here"
Only use the following tables:
{table_info}
Question: {input}"""
context_prompt = PromptTemplate(
input_variables=["input", "table_info", "top_k"],
template=_googlesql_prompt,
)
#passing question to the prompt template
final_prompt = context_prompt.format(input=data_question, table_info=table_name, top_k=10000)
# Pass final prompt to our chain
output = llm_db_chain(final_prompt)
return output['result'], output['intermediate_steps'][0]
# Running the function which outputs our results
llm_bq_sql_agent(data_question=<write_desired_data_question_in_natural_language>,
engine=engine,
table_name=cfg.TABLE_NAME
)
Conclusion
To conclude there is alot of freedom when it comes to creating your own sql agent which you can experiment with by tweaking the various components. Some interesting areas might be:
- Trying out other models
- Typically as newer models are released the quality might improve need to test this.
- Changing the context of the prompt.
- Perhaps a few examples could be added to leverage few should capabilities?
- Enhancing the chaining functionality.
- Additional components could be added enhancing the capabilities (web access, pdfs etc).