Table of Contents
Motivation: I believe with the recent developments of advanced open/closed source LLMs many applications can be created or enhanced in ways that were not possible before. This realisation has led me to begin trying to understand promising software which can aid in the utilisation of these models upon which I found this.
What is it?
Langchain can be thought of as a framework that can be used to incoporate LLMs into your applications. As has been shown recently, Large Language Models definetly have many use cases however using them alone in-silo has it’s limitations, Langchain provides features which can help accelerate this.
Resources
Plenty of nice resources are available, link to a few useful ones:
- Langchain Docs
- Good starting place to understand langchain, still in it’s early days but even so a nice place to get started.
- Langchain Github Repo
- Langchain Twitter page
- Many people post interesting and sometimes useful info which Langchain then retweets.
- Useful to track.
- Medium tutorial article
- Nice overview of various aspects of Langchain.
- Langchain YouTube channel
- Walkthroughs on how to use Langchain.
- Plenty of webinar style videos where upcoming developers/ startup founders show how they are using Langchain to build apps.
- Short Datacamp Langchain tutorial
- Goes over the basics along with providing further reading material.
Use cases
Some interesting use cases exist where Langchain can really help tie alot of things together. Langchain even provide a list of use cases as part of their documentation.
A few of the key building blocks that we will see across the various applications can be visualised as shown below.
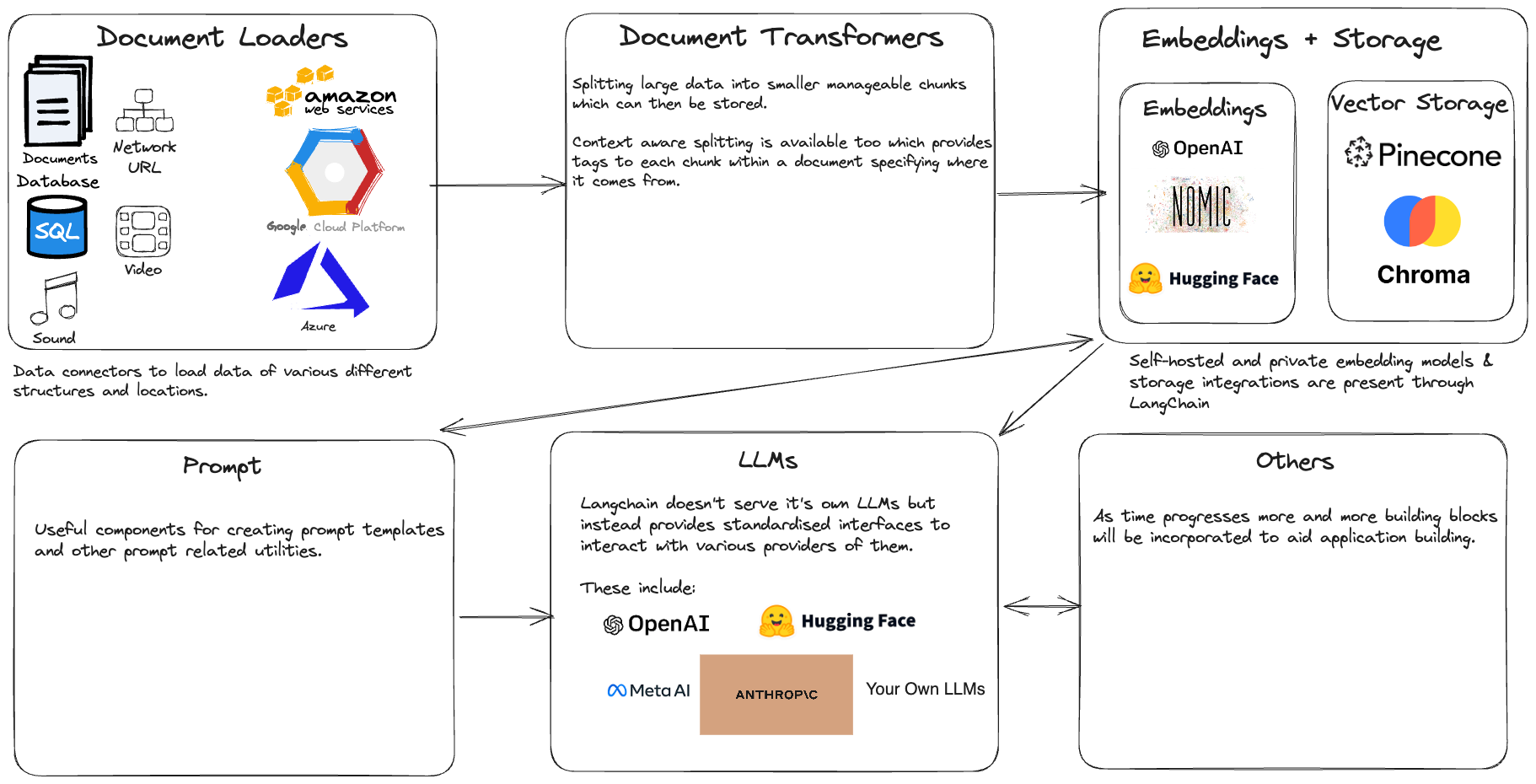
By using Langchain to bring together all these technologies unlocks the potential to build useful applications quickly.
Retrieval Augemented Generation (RAG)
The key idea here is that LLMs by themselves are great but not always perfect when it comes to providing factual information since it uses it’s own vast internal representations to produce output which may or may not be well versed in the particular topic you’re asking about. As a result it’s important to try and “augment” the the way they produce output by giving them access to additional information which relates to the questions you may have improving it’s ability to output good responses. A good illustration of this is provided below.
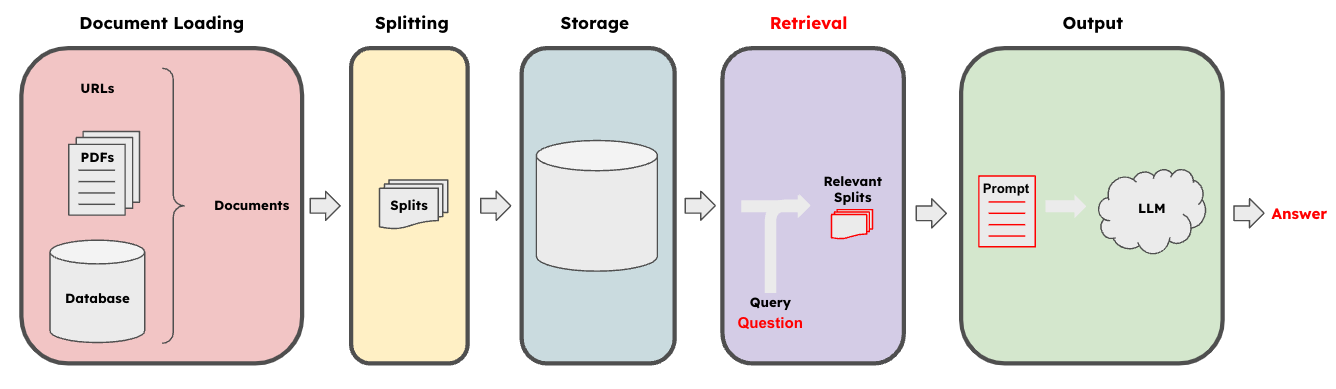
As we can see the cool feature is the purple retrieval block which handles taking your query/question and mapping it to an appropriate embedding vector which can then be compared against your stored document embeddings by something like a similarity search functionality to find the documents which are most relevant your query. These are then all fed into your prompt.
Langchain has a few different APIs to perform RAG.
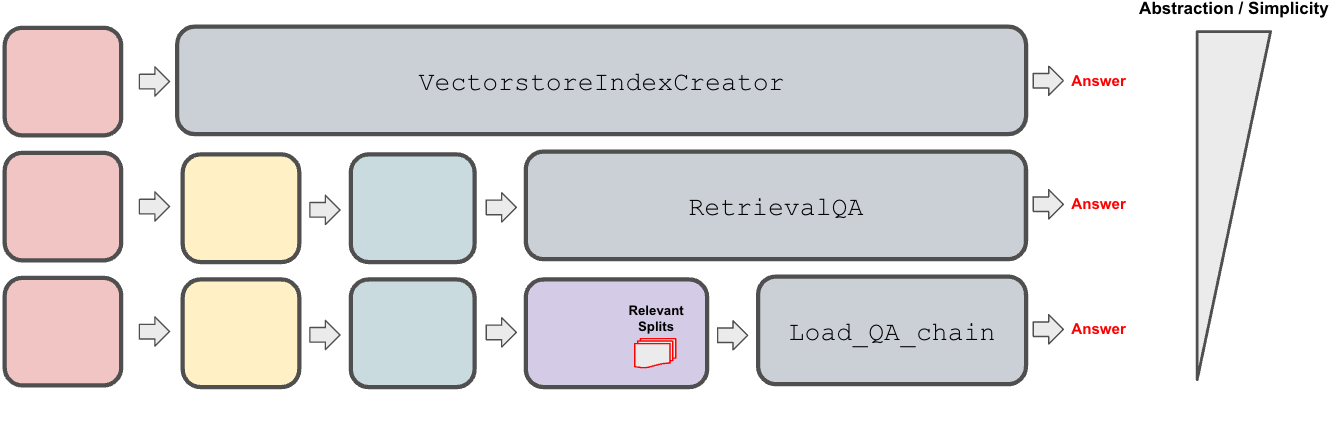
Summarization
Alot of times businesses will have a huge amounts of text data and more often then not it can take ages to understand the content usually leading to a few well known domain experts who are need to be questioned whenever you want to understand it. This is where summarization can come in very handy as you can get fast summarises quickly if you leverage LLMs in the right way.
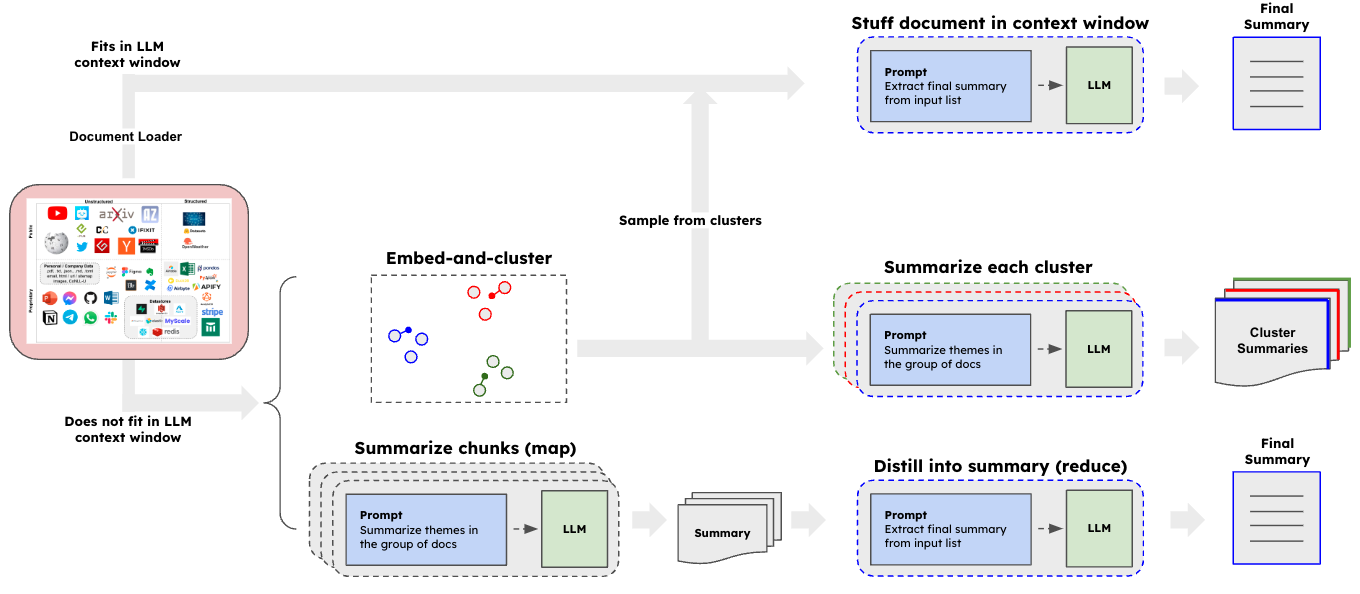
As we can see multiple paths exist to get our summaries, the most convienient being if we can fit the entire document itself into the context window of our model in which case we can just pass it in along with a prompt telling the model to summarize our documents. However more often than not this isn’t the case which means we can either embed the documents and perform clustering upon which we can either summarise all documents corresponding to each of the cluster groups (prompting the model to summarise themes for each cluster) or sample from the clusters to gain representative documents and then summarise those. Otherwise you can just split your documents up into individual chunks and then summarise each chunk and feed those summaries into the LLM asking it to summarise all the summaries (giving you a final summary which is the “summary of summaries”).
Getting Structured Output
When working with various applications you typically need your inputs and outputs to be in a particular format say csv, tsv, txt, json etc. It doesn’t seem that obvious that LLMs could provide great value here but they can.
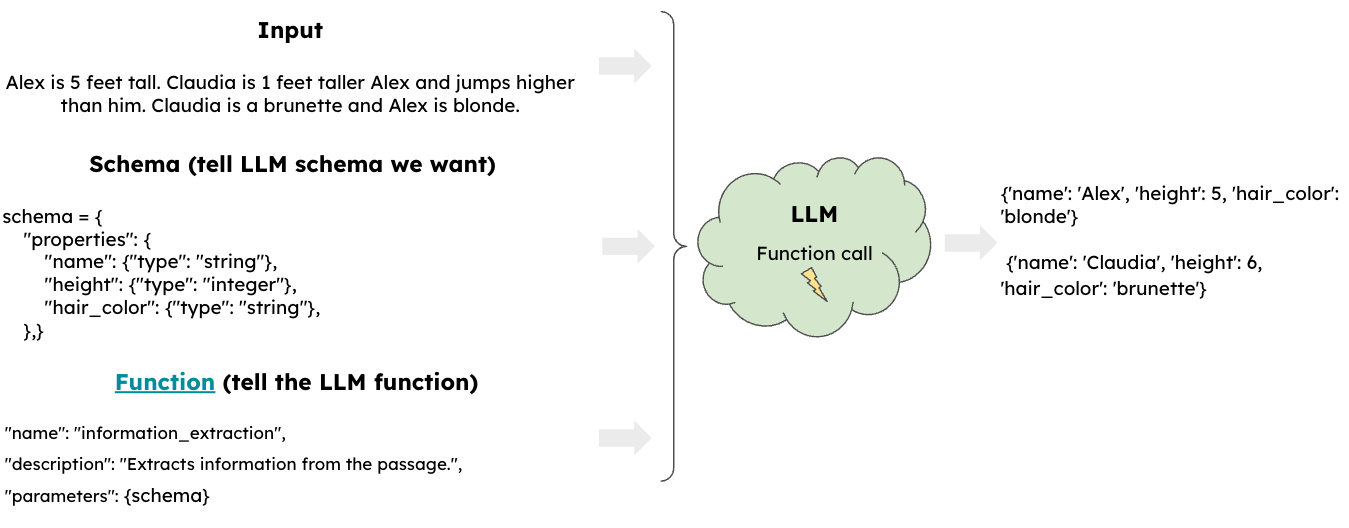
Essentially you can feed in your input along with the desired schema you’d like it to take and a function which can operate on the input and provide your desired output in the specified schema format to the LLM which can then create your desired output.
Text-SQL: SQL Coding Agents
Usually when working with data alot of us would have encountered the SQL query language in some form or another however many would rather steer away from it. After all when constructing a query we usually start off with writting down what we actually want out (using natural language) and then work our way out to actually writting the query. This is where a SQL agent formed by leveraging LLMs can come in real handy.
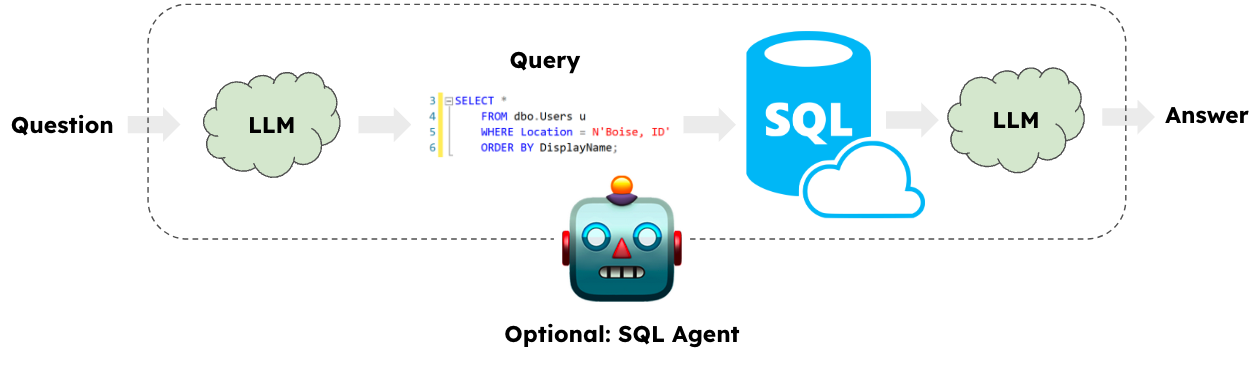
The idea is that you start of with some question that you want answered from your data using SQL, you then feed that question into and an LLM alongside your database table schema, some sample data etc and it can create a SQL query for you. This query can then be routed through and run against your DB providing an output which can then be fed back into your LLM for post processing providing your answer in an easy to understand way.
Chat Bot: Persisting Conversation Memory
We are all familiar with ChatGPT the application which allows you to create a dialogue with an LLM model. This application is built on a very similar premise, allowing the LLM the ability to retain some history of the conversation by feeding the previous responses back to the model and maintaining it in the context window.
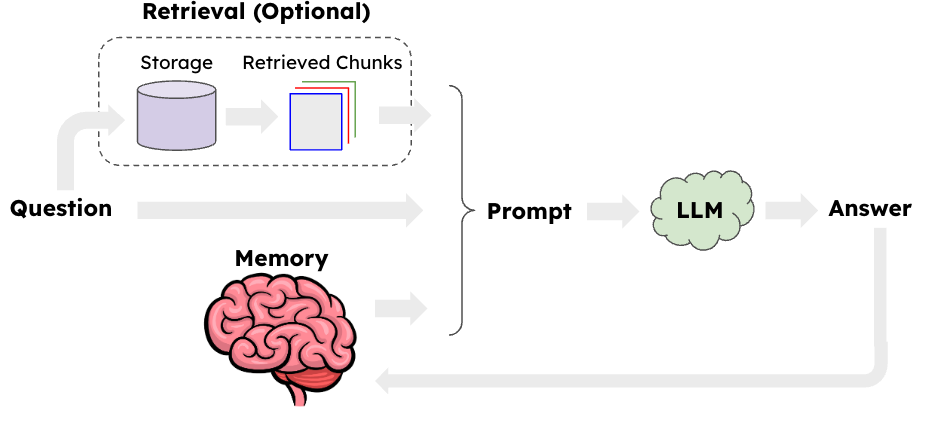
However the optional enhancement hear is that you can also incorporate the retrieval process which allows you to have access to documents you have stored away during your chat conversations. This is not something that ChatGPT has the ability to do.