Table of Contents
- Introduction
- How Generative AI Transforms Intent Classification
- Practical Walkthrough: Implementing Intent Classification with Generative AI
- Conclusion
- Resources and Further Reading
Introduction
Intent is really important! After all, it represents the “meaning behind the action”. For businesses it’s all about being able to understand your users along with potential users to better personalise your products & services to them which in turn increases the chances of retention or acquisition respectively.
Intent classification directly addresses this problem by trying to classify the potential intent behind an action observed from a user. Up until now many ways have been used which include training standard supervised learning classification models but what’s not caught on fully yet is how the recent advancements in GenAI have opened a range of possibilities when it comes to capitalising on this space, which is something we’re going to showcase in this post.
Below is a nice visual to get a feel for the overarching workflow:
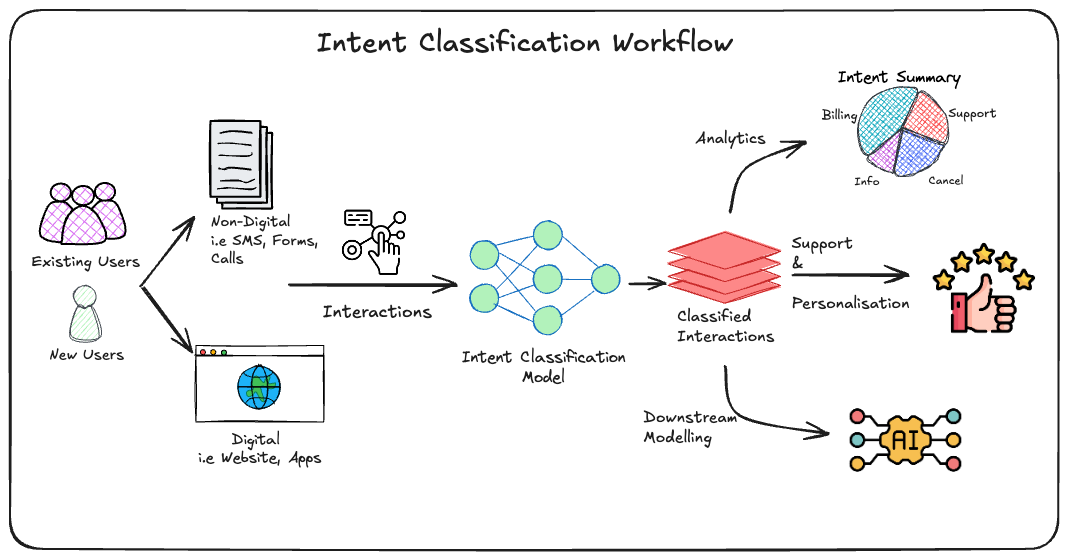
How Generative AI Transforms Intent Classification
- Traditional vs. Generative AI Approaches:
- Traditional ML models require extensive labeled datasets and feature engineering.
- Each additional step of traditional pre-processing risks information loss moving you bit by bit away from getting a true semantic understanding of the users input which is the key goal here.
- Generative AI models (e.g GPT based models) understand language context (alongside other modalities) deeply, even in noisy or incomplete inputs.
- Traditional ML models require extensive labeled datasets and feature engineering.
- Capabilities of GenAI in Intent Recognition:
- Understanding complex intents.
- Handling multimodalities or domain-specific queries.
- Learning with few-shot or zero-shot examples.
- Mass scalability (decoupling from human labour).
- Long term reduced costs (competition with the public/private sectors leading to costs being driven lower).
Practical Walkthrough: Implementing Intent Classification with Generative AI
Scenario
You are a business handling customer search queries on your website and want to classify intents into categories like “Product Inquiry,” “Order Status,” “Complaint,” etc. The key goals here are creating a solution that can understand the customers search query and classifiy it apporpriately enabling further downstream investigations.
An old way of addressing the problem
A standard way of addressing this would be heavily reliant on manual time and effort and would be relatively cumbersome involved as outlined below:
- Manually label a subset of the search queries data.
- Load in both the manually labelled portion along with the remaining unlabled samples.
- Perform some preprocessing to the labelled data by ensuring consistent white spacing.
- Essentially applying a function to the column.
- Identify intent labels with at least 5 sample records and remove those from labelled data that don’t meet this condition.
- This is done to the dataframe.
- Take the label counts (representative of the original df before the records were removed) and turn into a dataframe.
- Split the filtered data into a train and test set.
- Stratifying on the intent labels.
- Use TfidfVectorizer on the train set to learn and transform the test set, unlabelled set, and X pool (all the unlabelled query set).
- Define the
uncertainty_samplingfunctionality to select the most uncertain and certain samples based off predictions on a given dataset.- We touched on this here.
- More uncertain if the max probabilities are smaller (scenario where they are all equal would give the maximum uncertainty).
- Train a logistic regression model on the train set.
- Logreg internally handles text labels via label encoding and can be found via
clf.classes_.
- Logreg internally handles text labels via label encoding and can be found via
- Perform active learning loop for specified number of iterations:
- Iterations: Runs for
n_iterations(3 in this case). - Select Uncertain Samples: Uses
uncertainty_samplingto select the most uncertain samples from X_pool. - Human Labeling: Prompts the user to label these uncertain samples.
- Update Dataset: Adds the newly labeled samples to the training dataset.
- Retrain Model: Retrains the classifier with the updated dataset.
- Remove Labeled Instances: Removes the labeled instances from the pool.
- Evaluate Model: Evaluates the model’s performance on the test set and prints the accuracy for each iteration.
- Iterations: Runs for
- Train your final logistic regression model on the final set of data and predict classes of unlabelled data.
New GenAI approach
The idea here is to make use of the recent boom in generative modeling by utilising a in-context few-shot learning approach to assign labels based off pre-existing examples and set instructions. This can be used to generate the labels entirely by passing the need to training a model.
What makes this a good approach is :
- More powerful models have shown better & better emergent capabilties.
- Semantic understanding is one of the capabilities implying accurate intent understanding should be possible.
- Minimal (potentially no) need for manual labelling.
- Assuming a person takes several weeks to manually label this would easily save of the order of $1000’s.
A high level plan would involve:
Step 1: Problem Understanding and Data Preparation
- Objective Clarification: Understand the specific intents that need to be classified. Determine the set of intents we’d like to cater for and generate the problem involves classifying existing labels or generating new labels entirely.
- Data Collection: Gather a dataset of user search queries, along with any pre-existing labels, if available. This dataset will serve as the foundation for training and evaluating the intent classifier.
- Data Preprocessing: Clean and preprocess the search queries. This may include text normalization, tokenization, removing stop words, and handling special characters. Ensure the dataset is in a format compatible with the chosen LLM (check next step).
Given the context here we’d have a dataset of text based search queries (single column of text data containing the queries) but depending on the problem as hand this might not be the case e.g for audio calls you might have audio files corresponding to the interactions.
import pandas as pd
# Dummy data
user_search_queries = [
"Where is my order?",
"Can I return this item?",
"Do you sell eco-friendly products?",
"I’m unhappy with the service."
]
queries_df = pd.DataFrame(user_search_queries, columns=["search_query"])
Step 2: Model Selection
- Few-shot Learning Model Selection: Choose a state-of-the-art large language model (LLM) that supports few-shot learning, such as GPT-4o, Claude Sonnet 3.5 or similar models. Here we’ll look at open source ones.
- Framework and Tools: Determine the frameworks and tools required to implement the model. Options might include Hugging Face’s transformers library, OpenAI API, Llama.cpp or custom implementations depending on the infrastructure.
Irrespective of the model used you’d need to find a way to guiding the model to perform intent classification tasks. One way of doing this is defining an IntentClassifier class as shown below which can utilse the models capabilities in a way that enables intent classification.
Firstly before we get to that we will define some helper functionality for working with GCS.
import logging
import warnings
import gcsfs
from google.auth.exceptions import DefaultCredentialsError
from google.cloud import storage
def configure_logger():
"""
Configure the logger for the class.
RETURNS:
- self
"""
formatter = logging.Formatter("%(asctime)s [%(levelname)-5.5s] %(message)s")
logger = logging.getLogger()
logger.root.setLevel(logging.INFO)
logger.handlers = []
channel_handler = logging.StreamHandler()
channel_handler.setLevel(logging.INFO)
channel_handler.setFormatter(formatter)
logger.addHandler(channel_handler)
return logger
class StorageHelper:
"""
A helper class for interacting with Google Cloud Storage (GCS).
Methods
-------
connect_to_bucket()
Connect to a Google Cloud Storage bucket.
Attributes
----------
location : str
The GCP region location.
client : google.cloud.storage.Client
The GCS client used for interacting with GCS.
fs : gcsfs.GCSFileSystem
The GCS file system for additional file system operations.
"""
def __init__(
self,
location: Optional[str] = "europe-west2",
project: Optional[str] = None,
):
"""
Sets the logger from the shared tools package, the bigquery client object
with the above location, and the project name from the client object.
Parameters
----------
location : Optional[str], default = "europe-west2"
GCP region location
project_name : Optional[str], default = None
Name of the GCP project to connect to, default None
sets the project to the one you're currently working in
"""
self._logger = configure_logger()
self.location = location
try:
self.client = storage.Client(project=project)
except DefaultCredentialsError:
self.client = storage.Client.create_anonymous_client()
self.fs = gcsfs.GCSFileSystem(
project=self.client.project,
skip_instance_cache=True,
asynchronous=False,
loop=None,
)
def connect_to_bucket(self, bucket_name: str):
"""
Connect to a bucket and log the bucket details.
Parameters
----------
bucket_name : str
Name of the GCS storage bucket to connect to
"""
self.bucket = self.client.get_bucket(bucket_name)
self._logger.info(f"Bucket name: {self.bucket.name}")
self._logger.info(f"Bucket location: {self.bucket.location}")
self._logger.info(f"Bucket storage class: {self.bucket.storage_class}")
self._logger.info(f"Connected to bucket {self.bucket}")
Now here is the IntentClassifier logic:
import os
import torch
import logging
from typing import List, Tuple, Optional, Dict
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig
from llama_cpp import Llama
class IntentClassifier:
"""
A class to handle intent classification using either the Llama.cpp model or a Hugging Face model.
Parameters
----------
config : dict
A configuration dictionary containing settings for model loading, storage, and model-specific options.
"""
def __init__(self, config: Dict):
"""
Initialize the IntentClassifier object.
Parameters
----------
config : dict
A configuration dictionary that includes model and storage settings.
"""
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.config = config
self.use_llama_cpp = config.get("use_llama_cpp", False)
self.gcs = StorageHelper()
self.logger = configure_logger()
if self.use_llama_cpp:
model_gcs_path = os.path.join(
self.config["project_config"]["bucket"],
self.config["gcs"]["repo_name"],
self.config["gcs"]["model_folder"],
self.config["gcs"]["model_path"],
self.config["gcs"]["model_file"]
)
self._load_llama_cpp_model_from_gcs(model_gcs_path)
else:
model_gcs_path = os.path.join(
self.config["project_config"]["bucket"],
self.config["gcs"]["repo_name"],
self.config["gcs"]["model_folder"],
self.config["gcs"]["model_path"]
)
tokenizer_gcs_path = os.path.join(
self.config["project_config"]["bucket"],
self.config["gcs"]["repo_name"],
self.config["gcs"]["model_folder"],
self.config["gcs"]["tokenizer_path"]
)
self._load_model_and_tokenizer(model_gcs_path, tokenizer_gcs_path)
def _load_llama_cpp_model_from_gcs(self, model_gcs_path: str):
"""
Download and load the llama.cpp model from GCS.
Parameters
----------
model_gcs_path : str
The Google Cloud Storage path to the llama.cpp model file.
"""
local_model_path = f"/tmp/{self.config['gcs']['model_folder']}/{self.config['gcs']['model_path']}"
if os.path.exists(local_model_path):
self.logger.info(f"Loading llama.cpp model from local path: {local_model_path}")
self._load_llama_cpp_model(local_model_path)
else:
self.logger.info(f"Downloading llama.cpp model from GCS: {model_gcs_path}")
self._download_single_file_from_gcs(model_gcs_path, local_model_path)
self._load_llama_cpp_model(local_model_path)
def _load_llama_cpp_model(self, model_path: str):
"""
Load the llama.cpp model from a local path using llama-cpp-python.
Parameters
----------
model_path : str
The path to the llama.cpp model file.
"""
try:
self.logger.info(f"Loading llama.cpp model from {model_path}")
self.llama_model = Llama(model_path, n_ctx=512)
self.logger.info("Llama.cpp model loaded successfully")
except Exception as e:
self.logger.error(f"Error loading llama.cpp model: {e}")
raise
def _load_model_and_tokenizer(self, model_gcs_path: str, tokenizer_gcs_path: str):
"""
Load the Hugging Face model and tokenizer from GCS.
Parameters
----------
model_gcs_path : str
The GCS path to the model.
tokenizer_gcs_path : str
The GCS path to the tokenizer.
"""
local_model_path = f"/tmp/{self.config['gcs']['model_folder']}/model"
local_tokenizer_path = f"/tmp/{self.config['gcs']['model_folder']}/tokenizer"
if os.path.exists(local_model_path) and os.path.exists(local_tokenizer_path):
self.logger.info("Loading model and tokenizer from local paths.")
self._load_from_local(local_model_path, local_tokenizer_path)
else:
self.logger.info("Local paths not found, downloading from cloud storage.")
self._download_from_gcs(model_gcs_path, local_model_path)
self._download_from_gcs(tokenizer_gcs_path, local_tokenizer_path)
self._load_from_local(local_model_path, local_tokenizer_path)
def _download_single_file_from_gcs(self, gcs_path: str, local_path: str):
"""
Download a single file from GCS to a local path.
Parameters
----------
gcs_path : str
The GCS path to the file.
local_path : str
The local path where the file will be saved.
"""
try:
bucket, directory = io.get_bucket_info(gcs_path)
self.gcs.connect_to_bucket(bucket)
if not os.path.exists(os.path.dirname(local_path)):
os.makedirs(os.path.dirname(local_path))
blob = self.gcs.bucket.blob(directory)
blob.download_to_filename(local_path)
self.logger.info(f"Downloaded {local_path} from GCS.")
except Exception as e:
self.logger.error(f"Error downloading from GCS: {e}")
raise
def _download_from_gcs(self, model_gcs_path: str, tokenizer_gcs_path: str, local_model_path: str, local_tokenizer_path: str):
"""
Download the model and tokenizer from GCS and save them locally.
Parameters
----------
model_gcs_path : str
The GCS path to the model files.
tokenizer_gcs_path : str
The GCS path to the tokenizer files.
local_model_path : str
The local directory where the model will be saved.
local_tokenizer_path : str
The local directory where the tokenizer will be saved.
"""
for gcs_path, local_path in [(model_gcs_path, local_model_path), (tokenizer_gcs_path, local_tokenizer_path)]:
bucket, directory = io.get_bucket_info(gcs_path)
self.gcs.connect_to_bucket(bucket)
component = directory.split('/')[-1]
self.logger.info(f"Component: {component}")
if not os.path.exists(local_path):
os.makedirs(local_path)
blobs = list(self.gcs.bucket.list_blobs(prefix=directory))
for blob in blobs:
filename = blob.name.split('/')[-1]
blob.download_to_filename(os.path.join(local_path, filename))
self.logger.info(f"Downloaded {filename} from GCS.")
self._load_from_local(local_model_path, local_tokenizer_path)
def _load_from_local(self, model_path: str, tokenizer_path: str):
"""
Load the model and tokenizer from local paths.
Parameters
----------
model_path : str
The local path to the model.
tokenizer_path : str
The local path to the tokenizer.
"""
try:
self.model = AutoModelForCausalLM.from_pretrained(model_path, local_files_only=True).to(self.device)
self.logger.info("Hugging Face model loaded successfully from local path!")
except Exception as e:
self.logger.error(f"Error loading Hugging Face model: {e}")
raise
try:
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_path, local_files_only=True)
self.logger.info("Tokenizer loaded successfully from local path.")
except Exception as e:
self.logger.error(f"Error loading tokenizer: {e}")
try:
self.tokenizer = AutoTokenizer.from_pretrained(model_path, local_files_only=True)
self.logger.info("Tokenizer loaded from model path as fallback.")
except Exception as fallback_e:
self.logger.error(f"Error loading tokenizer from fallback: {fallback_e}")
raise
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
def classify(self, query: str, prompt_template: str, few_shot_examples: Optional[List[Tuple[str, str]]] = None) -> str:
"""
Classify the intent of a given query using either llama.cpp or Hugging Face model.
Parameters
----------
query : str
The query to classify.
prompt_template : str
The template to use for generating prompts.
few_shot_examples : Optional[List[Tuple[str, str]]], optional
A list of few-shot examples to include in the prompt, by default None.
Returns
-------
str
The predicted intent for the query.
"""
try:
if few_shot_examples:
examples_text = "\n".join(f"Query: {example}\nIntent: {label}" for example, label in few_shot_examples)
prompt = prompt_template.format(examples=examples_text, query=query)
else:
prompt = prompt_template.format(query=query)
if self.use_llama_cpp:
return self._llama_cpp_classify(prompt)
else:
return self._hf_classify(prompt)
except Exception as e:
self.logger.error(f"Error classifying query: {e}")
raise
def _llama_cpp_classify(self, prompt: str) -> str:
"""
Classify a query using the llama.cpp model.
Parameters
----------
prompt : str
The formatted prompt for the llama.cpp model.
Returns
-------
str
The predicted intent from the model output.
"""
try:
output = self.llama_model(prompt, max_tokens=10, temperature=0.0)
generated_text = output["choices"][0]["text"].strip()
self.logger.info(f"Generated text: {generated_text}")
generated_lines = generated_text.strip().split("\n")
for line in generated_lines:
line = line.strip()
if line:
predicted_intent = line.strip()
break
return predicted_intent
except Exception as e:
self.logger.error(f"Error in llama.cpp classification: {e}")
raise
def _hf_classify(self, prompt: str) -> str:
"""
Classify a query using the Hugging Face model.
Parameters
----------
prompt : str
The formatted prompt for the Hugging Face model.
Returns
-------
str
The predicted intent from the model output.
"""
inputs = self.tokenizer.encode_plus(
prompt,
return_tensors='pt',
padding=True,
truncation=True,
max_length=512,
)
input_ids = inputs['input_ids'].to(self.device)
attention_mask = inputs['attention_mask'].to(self.device)
with torch.no_grad():
outputs = self.model.generate(
input_ids,
attention_mask=attention_mask,
max_new_tokens=10,
num_return_sequences=1,
temperature=0.3,
eos_token_id=self.tokenizer.encode('\n')
)
generated_text = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
predicted_intent = generated_text.split("Intent:")[-1].strip().split()[0]
return predicted_intent
def batch_classify(self, queries: List[str], prompt_template: str, few_shot_examples: Optional[List[Tuple[str, str]]] = None) -> List[str]:
"""
Batch classify a list of queries.
Parameters
----------
queries : List[str]
A list of queries to classify.
prompt_template : str
The template to use for generating prompts.
few_shot_examples : Optional[List[Tuple[str, str]]], optional
A list of few-shot examples to include in the prompts, by default None.
Returns
-------
List[str]
A list of predicted intents for each query.
"""
try:
results = []
for query in queries:
intent = self.classify(query, prompt_template, few_shot_examples)
results.append(intent)
return results
except Exception as e:
self.logger.error(f"Error in batch classification: {e}")
raise
What’s handy about the above functionality is it incorporates the ability to perform classification using both HuggingFace and Llama.cpp based models in an offline fashion where the required files to use a model are manually downloaded and stored inside a location (Google Cloud Storage here) and loaded into a tmp directory on your local instance.
To initialise the model all you need to do is specify a config file/ dictionary pointing to the model in storage along with the relevant paths.
Here is an example of initialising a HF model.
# HuggingFace GPT-2 model
gpt2_config = {
"project_config": {"bucket": "gs://<bucket-name>"},
"gcs": {
"project_name": "<project-name>",
"model_folder": "gpt2-medium",
"model_path": "model",
"tokenizer_path": "tokenizer"
}
}
gpt2_classifier = IntentClassifier(config=gpt2_config)
Step 3: Few-shot Learning Setup
- Prompt Engineering: Design prompts for the LLM that effectively convey the task of intent classification. Develop few-shot examples to guide the model in understanding how to assign or generate labels.
- Prompt Testing: Test the initial prompts with a small sample of search queries to evaluate the model’s ability to classify intents accurately. Fine-tune the prompts based on the results.
We can experiment with a range of different templates (examples provided below). This is widely considered an art at this stage known as “prompt engineering” and no single prompt works best with a given model.
Tip: It’s best to always experiment when it comes to prompting and get a feel for what works best for a given model. Make use of prompt engineering guides and the resources available on the model creators docs as reference. Keeping upto date on online forum discussions and videos are also a good way to build a sense of what works and doesn’t.
Here is a basic prompt to get started:
import textwrap
prompt_template = textwrap.dedent("""
Classify the intent of the following queries:
Examples:
{examples}
Query: {query}
Intent:
""").strip()
Step 4: Model Generation and Evaluation
- Initial Classification: Use the few-shot setup to classify intents for the entire dataset. Evaluate the performance of the model by comparing its classifications with any pre-existing labels.
- Performance Metrics: Define and calculate metrics such as accuracy, precision, recall, and F1-score to quantify the model’s performance. Consider qualitative evaluation as well, especially if generating new labels.
- Error Analysis: Identify any recurring errors or misclassifications. Analyze whether they result from insufficient few-shot examples, ambiguous queries, or model limitations.
Here is a good example of using the class to classify an example query.
few_shot_intent = gpt2_classifier.classify(
query="My broadband subscription is bad, how do I cancel?",
prompt_template=prompt_template,
few_shot_examples=[
("How do I upgrade my phone plan?", "upgrade-service"),
("I have a question about my last bill", "billing-inquiry"),
("My internet is not working", "technical-support")
]
)
print(f"Few-shot intent: {few_shot_intent}")
which generates:
Few-show intent: cancel-service
The batch functionality also works by looping over the set of search queries you may have and classifying them.
# Sample the dataframe
sample_size = 100
sampled_df = queries_df.sample(n=sample_size, random_state=42)
# Get the list of sampled queries
sampled_queries = sampled_df['search_query'].tolist()
# Classify the sampled queries
intents = gpt2_classifier.batch_classify(
queries=sampled_queries,
prompt_template=prompt_template,
few_shot_examples=[
("How do I upgrade my phone plan?", "upgrade-service"),
("I have a question about my last bill", "billing-inquiry"),
("My internet is not working", "technical-support")
]
)
# Create a new DataFrame with the original queries and intents
labelled_results = pd.DataFrame({
'search_query': sampled_queries,
'intent': intents
})
merged_results = queries_df.merge(labelled_results, on='search_query', how='left')
Step 5: Iterative Improvement
- Prompt Refinement: Based on the error analysis, refine the prompts and few-shot examples. Experiment with different prompt structures, additional context, or varied examples to improve classification accuracy.
- Model Selection: Utilising higher performing models likely to unlock better capabilties, Quantization might be worth exploring if memory/compute/costs are a concern.
- Feedback Loop: If available, incorporate feedback from human labelers or domain experts to iteratively improve the model’s classifications. Consider active learning strategies to further enhance performance.
This work can be extended in many ways. A few of these have been listed below; the key being that when applying these techniques you can make use of a golden dataset or an available source of truth to evaluate whether they’re having a tangible benefit for your use case.
Prompting
- Well crafted prompts (detailed yet concise) have been shown to yield better performance rather than basic ones.
Here are some more detailed prompt examples compared to those above:
import textwrap
prompt_template_1 = textwrap.dedent("""
You are an AI assistant for a telecommunications tech company. Your task is to classify the intent of customer search queries on the company's email.
The intent should be in the form <topic>-<sub-topic> that best describes the customer's primary goal or issue. The topic should fall under one of
the following categories:
- Billing: Issues related to charges, invoices, or payments.
- Technical: Problems with service, connectivity, or equipment.
- Upgrade: Requests to improve or change current services.
- Information: General inquiries about services or products.
- Cancel: Requests to end a service or subscription.
- Support: Requests for customer service or assistance.
Here are some example queries and their intents:
{examples}
Now, classify the following query:
Query: {query}
Intent:
""").strip()
prompt_template_2 = textwrap.dedent("""
As an AI assistant for a telecommunications tech company, your task is to determine the primary intent behind customer website search queries and emails.
Work step-by-step following these guidelines:
1. Analyze the query to understand the customer's main concern or request.
2. Choose a single-word intent that best captures the primary purpose of the query.
3. If multiple intents are present, select the most dominant or urgent one.
4. Use only the following intent categories for the topic:
- Billing: Payment, charges, invoices
- Technical: Service issues, connectivity problems
- Upgrade: Service improvements, plan changes
- Information: General inquiries, product details
- Cancel: Service termination
- Support: Customer assistance, general help
5. Ensure the <sub-topic> is as detailed as possible within each of the topic categories.
Examples:
{examples}
Now, classify this query:
Query: {query}
Intent:
""").strip()
Model Selection
- Some drawbacks of using more powerful models is the memory/compute they require along with latency requirements for using closed source API models.
- One way to combate this is to use efficient quantized versions of models who’s weights have been quantized thereby reducing the memory/compute footprint allowing for faster use of high performing models while keeping costs low and minimizing performance impacts.
# Quantized Phi-3.5 mini model
phi_35_min_instruct_config = {
"project_config": {"bucket": "gs://<bucket-name>"},
"gcs": {
"project_name": "<project-name>",
"model_folder": "Phi-3.5-mini-instruct-GGUF",
"model_path": "model",
"model_file": "Phi-3.5-mini-instruct-Q4_K_S.gguf"
},
"use_llama_cpp": True
}
# Initialize the classifier
phi_3_point_5_mini_instruct_quantized_classifier = IntentClassifier(
config=phi_35_min_instruct_config
)
qwen2_0_5b_instruct_config = {
"project_config": {"bucket": "gs://<bucket-name>"},
"gcs": {
"project_name": "<project-name>",
"model_folder": "Qwen2-0.5B-Instruct-GGUF",
"model_path": "model",
"model_file": "qwen2-0_5b-instruct-q4_k_m.gguf"
},
"use_llama_cpp": True
}
qwen2_instruct_classifier = IntentClassifier(config=qwen2_0_5b_instruct_config)
Conclusion
As we’ve seen the impact of GenAI in this space is large and will only continue to expand as capabilities in these areas improve. With the investments going into AI I antipate things aren’t going to slow down anytime so it’s worthwhile investing in exploring these techniques.
I recommend taking elements of the code shown here and adapting it for your use cases. Things are reletaively extensible.