Table of Contents
- What is Fine-Tuning?
- When to use Prompt Engineering vs RAG vs Fine-Tuning?
- Different Approaches to Fine-Tuning
- Key Steps in Supervised Fine-Tuning
- Three Options for Updating Model Parameters
- Implementing LoRA for Efficient Fine-Tuning
- Conclusion
- Resources
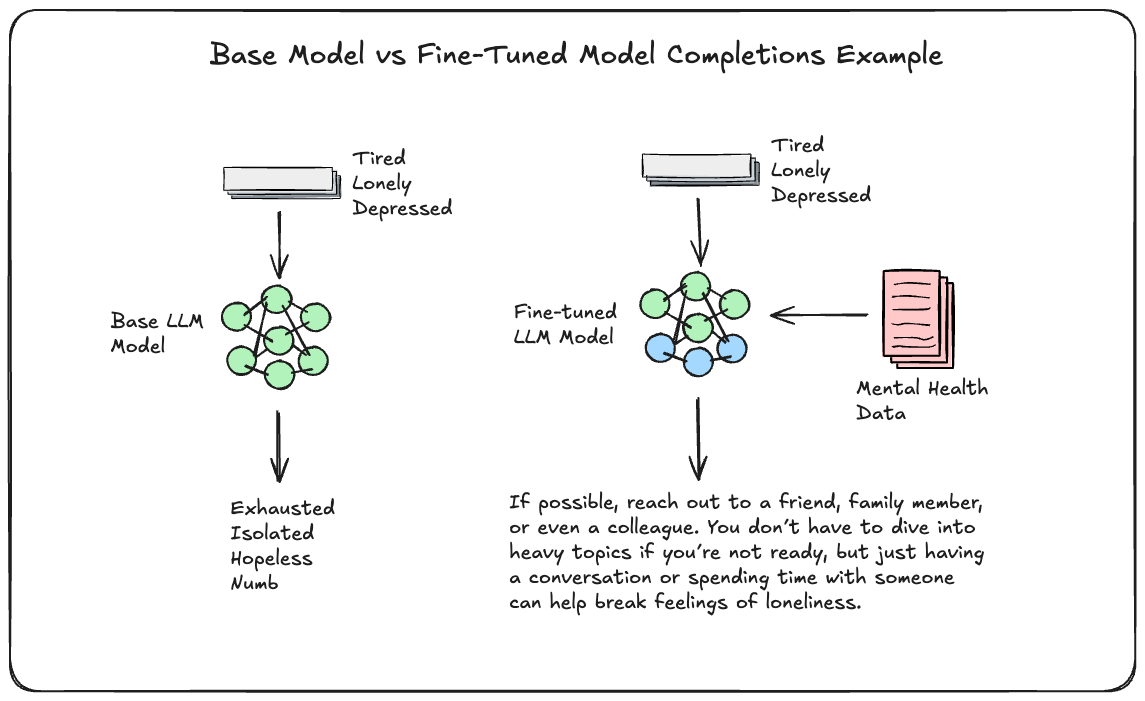
What is Fine-Tuning?
At its core, model fine-tuning involves taking an existing pre-trained language model, such as GPT-3, and modifying its internal parameters (weights) in the hopes to suit a specific task better. The model starts as a “rough diamond” with general capabilities, and fine-tuning refines it into a “polished diamond” more suitable for specific applications. For example, the old ChatGPT (GPT-3.5-turbo) was a fine-tuned version of GPT-3, optimised for interactive and conversational tasks as we touched on in our prior post.
Fine-tuning offers significant potential benefits, like improving model performance for a specialized task and even outperforming larger, non-fine-tuned models with fewer parameters. For example, OpenAI’s smaller fine-tuned InstructGPT model performed better than GPT-3 despite having far fewer parameters.
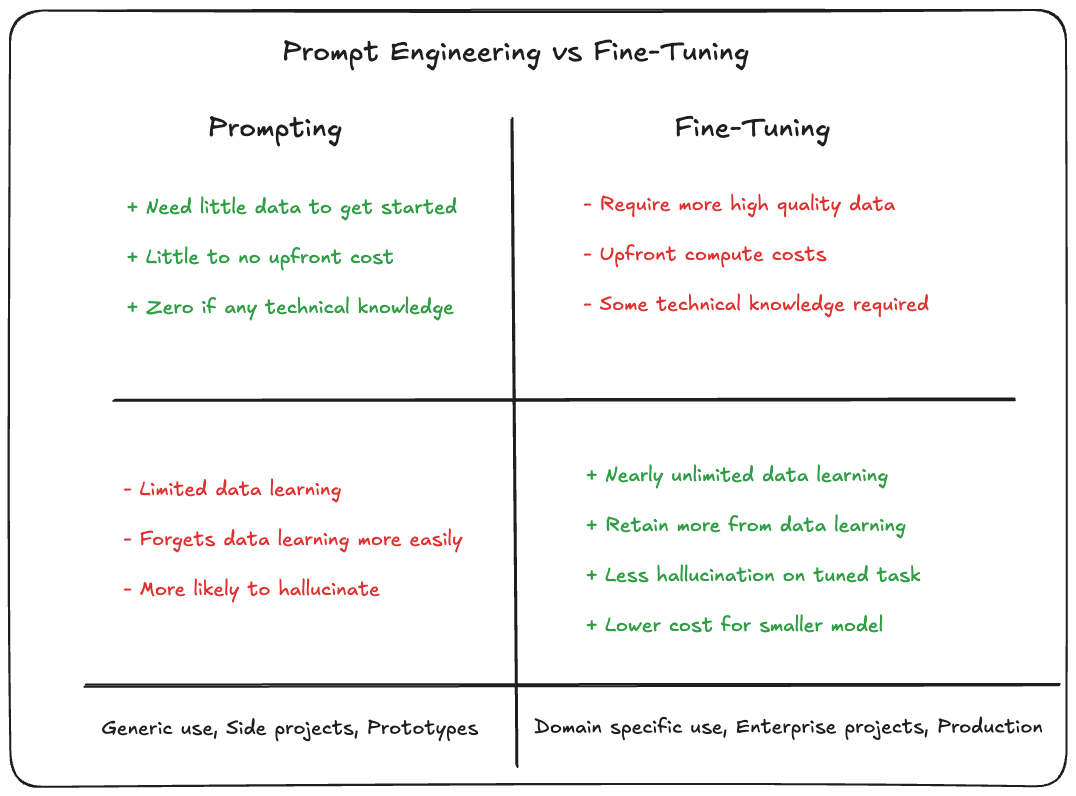
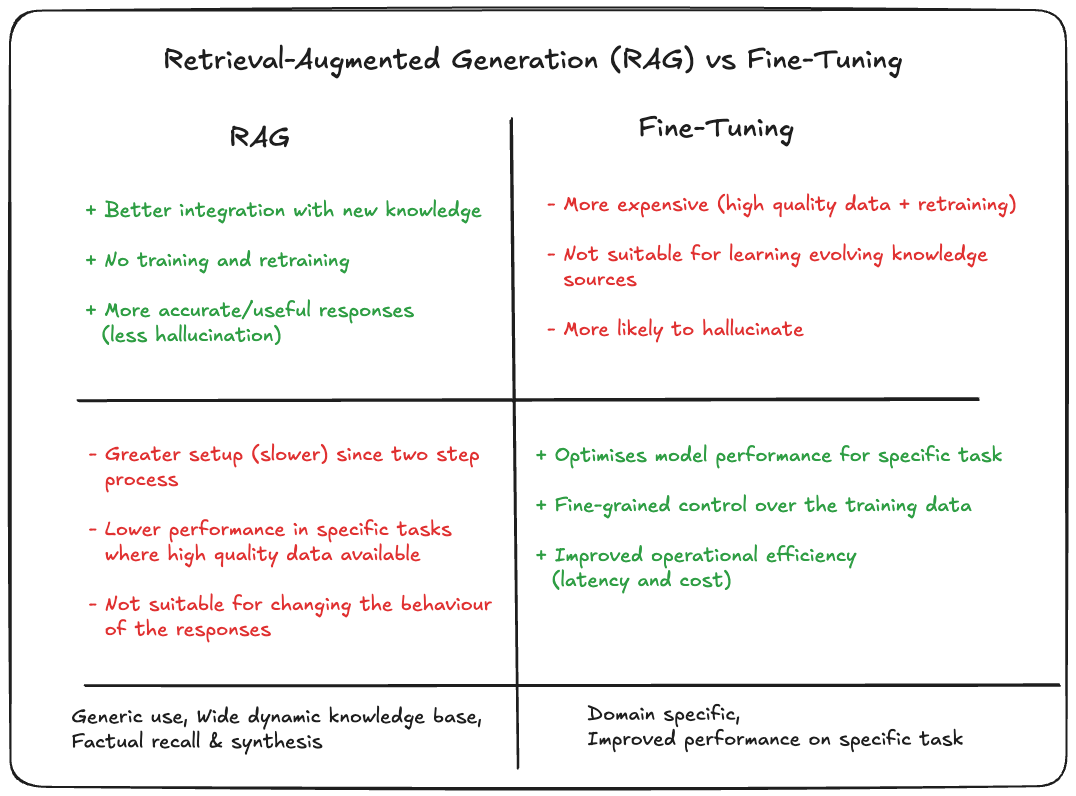
When to use Prompt Engineering vs RAG vs Fine-Tuning?
This enevitably is highly context dependent, things like your infrastructure, capabilities, use cases all will play a major part.
Here is a brief breakdown on the pros and cons that you can use to help gauge your choice.
Different Approaches to Fine-Tuning
- Self-Supervised Learning:
- This is the same approach used to train base models. In fine-tuning, you customize your training dataset to align with your specific application, for example, feeding the model with a specific style of text.
- Supervised Learning:
- In this method, you have input-output pairs in your dataset. For example, if you’re building a question-answering model, you’d train the model on pairs of questions and answers. You’d use prompt templates to generate a training corpus, helping the model learn how to generate appropriate responses.
- Reinforcement Learning:
- OpenAI’s InstructGPT model uses a combination of reinforcement learning to refine model performance. This involves training a reward model that scores the outputs of the language model, then fine-tuning the model based on those scores.
Key Steps in Supervised Fine-Tuning
The video focuses on the supervised learning approach to fine-tuning, which involves these five steps:
- Choose Your Fine-Tuning Task:
- This could range from text summarization to classification tasks, like sentiment analysis or binary text classification.
- Prepare Your Training Dataset:
- Your dataset should contain input-output pairs related to your task. For example, in text summarization, you’ll need text inputs with corresponding summary outputs.
- Select a Base Model:
- There are many large language models available, such as GPT-3, LLaMA, or even fine-tuned variants. Choose a model based on your needs.
- Fine-Tune the Model:
- Use supervised learning techniques to fine-tune the parameters of the base model to suit your task.
- Evaluate Model Performance:
- Once the model is fine-tuned, measure its performance using relevant evaluation metrics such as accuracy or F1 score.
Three Options for Updating Model Parameters
During fine-tuning, different approaches can be taken to adjust the model’s parameters:
- Full Parameter Fine-Tuning:
- All model parameters are retrained, but this method is computationally expensive, especially with models having billions of parameters.
- Transfer Learning:
- A more efficient approach where only the last few layers of the model (the “head”) are fine-tuned. This approach costs less in terms of computational resources.
- Parameter-Efficient Fine-Tuning (PEFT):
- This approach adds additional parameters instead of retraining the existing ones, using fewer resources. One popular technique under this is LoRA (Low-Rank Adaptation). LoRA adds a small set of trainable parameters to the model, allowing effective fine-tuning with significantly fewer trainable weights.

Implementing LoRA for Efficient Fine-Tuning
We’ll now take a look at a hands-on example of fine-tuning a language model using the LoRA technique, which significantly reduces the number of trainable parameters while still achieving good performance.
Efficient Model Fine-Tuning with LoRA for Text Generation
In this section, we’ll explore how to efficiently fine-tune a pre-trained text generation model using Low-Rank Adaptation (LoRA), which significantly reduces computational resource requirements. We’ll utilize the peft package to apply LoRA, bitsandbytes for quantization, and libraries like transformers, accelerate, and trl to streamline the workflow. Instead of using a smaller model like DistilBERT, we’ll fine-tune a GPT-like text generation model, showcasing how LoRA can adapt larger models with limited resources.
Step 1: Set Up the Base Model
We’ll start by loading a pre-trained text generation model from the transformers library. In this case, we’ll use gpt2 for its compactness and fast iteration.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import bitsandbytes as bnb
# Load GPT-2 model and tokenizer
model_name = "gpt2"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Enable gradient checkpointing to save memory
model.gradient_checkpointing_enable()
In the code above:
- We load the
gpt2model and tokenizer using thetransformerslibrary. - The model is loaded with
bitsandbytesin 8-bit precision (load_in_8bit=True) to reduce memory usage and accelerate training. This is useful when fine-tuning large models with limited GPU resources. - Gradient checkpointing is enabled to save additional memory during backpropagation.
Step 2: Prepare the Dataset
Next, we prepare the dataset, tokenize it, and ensure consistency in input lengths. For demonstration purposes, we will use a dummy dataset, but you can substitute it with any text dataset, such as IMDb movie reviews or a custom dataset.
from datasets import load_dataset
# Load IMDb movie reviews dataset for text generation tasks
dataset = load_dataset("imdb")
# Tokenize the dataset
def tokenize_function(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=512)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Prepare input IDs and attention masks
train_dataset = tokenized_datasets["train"].shuffle().select(range(1000)) # Reduce size for faster demonstration
This step involves:
- Loading a dataset (IMDb movie reviews, in this case) using the
datasetslibrary. - Tokenizing the text using the
tokenizer, ensuring consistent input length through truncation and padding. - Preparing a smaller subset of the dataset for faster iteration during training.
Step 3: Configure LoRA Parameters
We now configure LoRA parameters, such as intrinsic rank and dropout probability, and apply them to the model layers using the peft package. LoRA will adapt specific layers while keeping the base model frozen, minimizing the number of trainable parameters.
from peft import LoraConfig, get_peft_model
# Define LoRA configuration
lora_config = LoraConfig(
r=8, # Intrinsic rank
lora_alpha=16, # Scaling factor for updates
lora_dropout=0.1, # Dropout rate for LoRA layers
target_modules=["c_attn", "mlp"], # Target modules to apply LoRA to
bias="none"
)
# Apply LoRA to the model
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
Here:
LoraConfigdefines the LoRA parameters:r(intrinsic rank): Controls the rank of the low-rank update matrix.lora_alpha: Scaling factor applied to the LoRA updates.lora_dropout: Probability of dropout to regularize the training process.target_modules: Specifies the model layers where LoRA will be applied (e.g., the attention and MLP layers of GPT-2).
- The
get_peft_modelfunction wraps the base model with LoRA, enabling it to adapt efficiently during training.
Step 4: Fine-Tune the Model
With the model wrapped in LoRA and the dataset prepared, we can fine-tune it. We’ll use the trl library’s SFTTrainer for supervised fine-tuning, and accelerate for multi-GPU or distributed training if available.
from transformers import TrainingArguments
from trl import SFTTrainer
from accelerate import Accelerator
# Set up Accelerator for distributed training (if available)
accelerator = Accelerator()
# Define training arguments
training_args = TrainingArguments(
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
learning_rate=5e-5,
num_train_epochs=3,
gradient_accumulation_steps=4,
fp16=True, # Mixed precision for faster training
logging_dir='./logs',
output_dir='./results',
save_total_limit=2,
save_steps=500,
logging_steps=100
)
# Initialize SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
accelerator=accelerator,
)
# Fine-tune the model
trainer.train()
Key elements:
TrainingArgumentssets up important training configurations like batch size, learning rate, number of epochs, gradient accumulation, and mixed precision (FP16) for faster training.SFTTrainerfrom thetrllibrary provides an easy interface for supervised fine-tuning. It integrates well withacceleratefor multi-GPU or distributed setups.
With this approach, you can fine-tune large text generation models like GPT-2 efficiently by leveraging Low-Rank Adaptation (LoRA) with peft, quantization with bitsandbytes, and distributed training with accelerate. The use of LoRA ensures that only a few trainable parameters are updated during training, while most of the base model remains frozen, drastically reducing the computational overhead.
Conclusion
Fine-tuning large language models allows developers to build specialized applications tailored to unique tasks, without the need for training a model from scratch. By leveraging techniques like LoRA and supervised fine-tuning, it’s possible to reduce costs while still achieving excellent performance. Whether you’re building models for sentiment analysis, question-answering, or any other application, fine-tuning is a powerful tool to make LLMs work for you.
If you’re interested in learning more about fine-tuning or exploring more code examples, be sure to check out additional resources like the Towards Data Science blog or the Hugging Face documentation.
Resources
- Hugging Face PEFT documents
- Great intro point into performing PEFT techniques, includes but goes beyond just LoRA.
- Recommend checking out and utilising the techniques that suit your workflow the most.
- DeepLearning AI efficient Llama-v2-7b finetuning example
- Deeper dive into specific details and problems you may encountering when practically trying to fine-tune via examples.
- Maxime Labonne finetuning overview talk
- Fairly short and concise overview of finetuning and merging techniques. Useful to get a fast understanding.