Table of Contents
- Resources
- Introduction to Docker
- Docker Virtualization vs Other Virtualization Strategies
- Getting Started with Docker
Resources
- Docker official docs
- Full set of resources including download instructions, reference API commands, tutorials etc.
- Docker for Data Science Datacamp tutorial
- Run down of how it’s useful along with practical code snipets and standard commands that you may encounter when using DS purposes.
Introduction to Docker
Docker first launched in 2013 and can be thought of as part of an opensource ecosystem (Docker Compose, Kubernetes etc form part of that larger ecosystem) which at it’s core focuses on making applications easy to run, deploy and scale.
This is done by leveraging the concept of containers, a lightweight, secure and easily portable bundle of all things necessary to run an application or workflow then leveraging this technology to ship and maintain real-world applications.
Formally speaking an image represents the bundle of all those items while an acutal running instance would be named as a container.
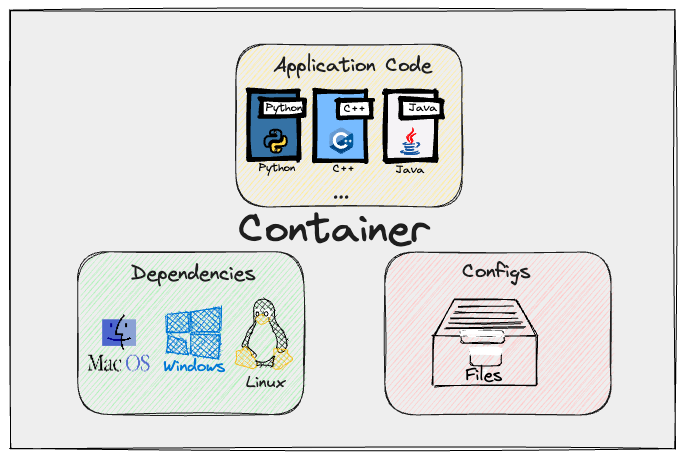
Note: It’s worthwhile noting that containers have been around for awhile before Docker but it’s Dockers release that got everyone excited about the technology and starting to use it extensively.
A core part of Docker is the Docker Engine which consists of a client-server design, client being the Docker CLI and server being the Docker Daemon.
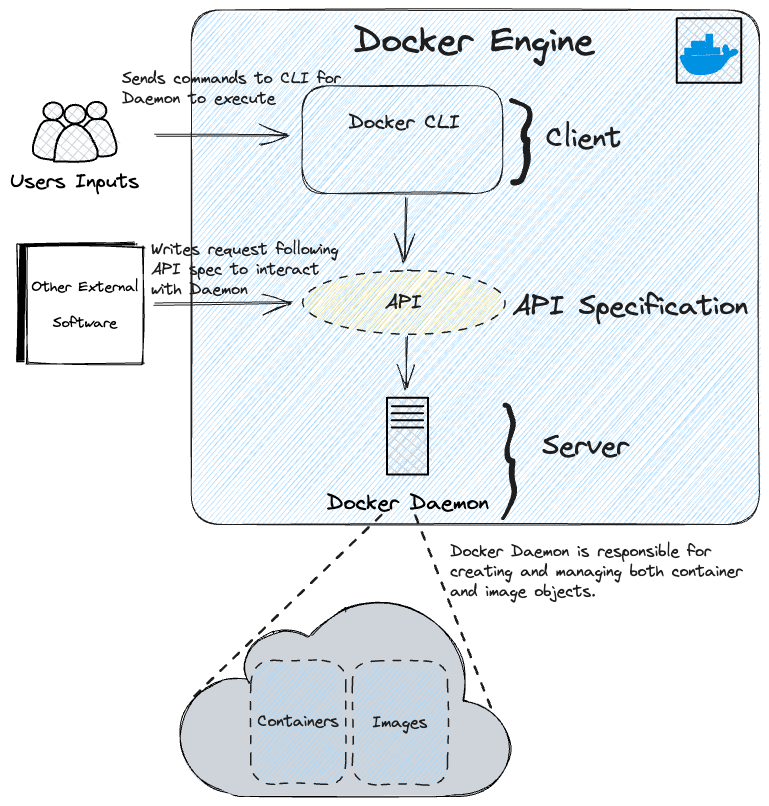
Docker Virtualization vs Other Virtualization Strategies
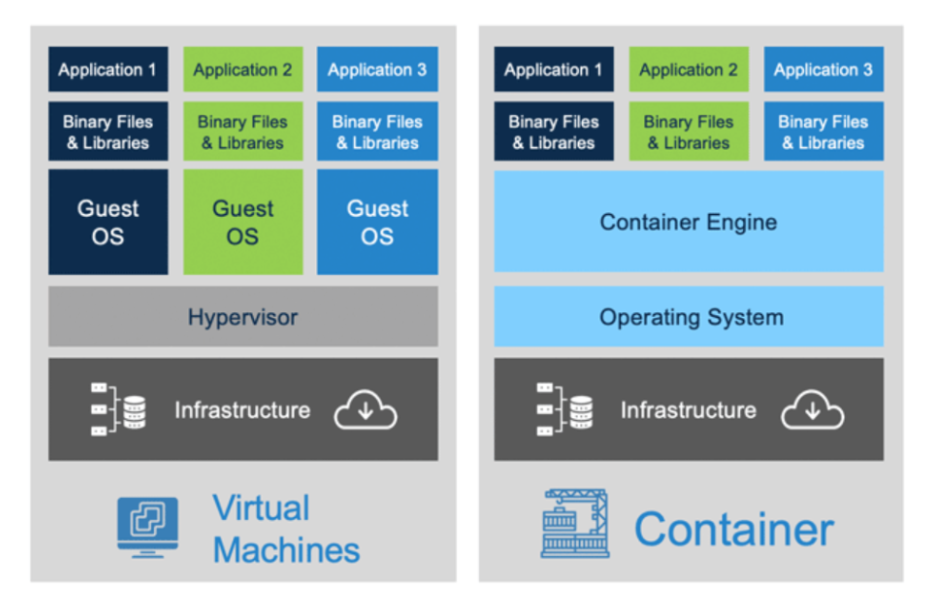
You don’t need containers to actually build applications a notable alternative has been virtual machines which have been really successful in recent times however usually the choice depends on your particular problem at hand, below as a quick reference table comparing the advantages vs disdvantages of both technologies across a range of areas.
| Features/Concerns | Containers | Virtual Machines |
|---|---|---|
| Advantages | ||
| Lightweight | - Share host OS kernel. | - Each VM runs its own OS. |
| - Faster startup and better resource usage. | ||
| Portability | - Easy to move across different environments. | - Less portable compared to containers. |
| Microservices | - Ideal for microservices architectures. | - Better suited for monolithic apps. |
| Scalability | - Easier and faster to scale. | - Slower to scale. |
| Resource Efficiency | - Higher due to shared OS kernel. | - Lower due to individual OS. |
| DevOps & CI/CD | - Promotes CI/CD. | - Less integrated with CI/CD. |
| Disadvantages | ||
| Isolation | - Less isolation. | - Strong isolation. |
| Kernel Dependency | - Dependent on host OS kernel. | - Independent OS for each VM. |
| Usage Scenarios | ||
| - Microservices, fast scaling, CI/CD. | - Strong isolation, monolithic apps. |
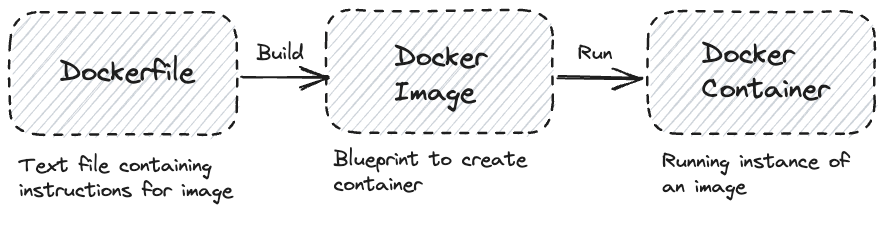
Getting Started with Docker
The typical workflow approach you’d take is you’d firstly create your application and know the dependencies that are required for it to run. For Data science applications for example that’d mean you python files, requirement files, version of python alongside additional config files. With these in mind you would generate a dockerfile which can be used to create your initial docker image and then run this docker image to create a container instance.
To do this it’s worthwhile knowing some useful shell commands in order to interact with the Docker Daemon:
# Creates a container from an image
docker run <image-name>
# Creates a container from an image and an interactive shell in the started container
docker run -it <image-name>
# Creates a container from an image in the background
docker run -d <image-name>
# Runs an image and assings it a particular name
docker run --name <container-name> <image-name>
# Stop a running container
docker stop <container-name>
# Removing a stopped container (still occupys hard drive space unless you perform this step)
docker container rm <container-id/ container-name>
# Lists out the running containers
docker ps
# Finds a particular container with some name
docker ps -f "name=<container-name>"
# Checking output generated from a container
docker logs <container-id>
# See live output generated from a container
docker logs -f <container-id/ container-name>
# Pulling the latest image from the docker hub
docker pull <image-name>
# Pulling a specific version image from the image hub
docker pull <image-name>:<image-version>
# Viewing the available images on your machine
docker images
# Removing images (only works if no running containers exist)
docker image rm <image-name>
# Removing all containers which have been stopped
docker container prune
# Remove all imgaes which don't have atleast one image
docker image prune -a
# Pulling a private image
docker pull dockerhub.myprivateregistry.com/image_name
# Pusing your own image to a registry and pushing to a private registry
docker tag <image-name> dockerhub.myprivateregistry.com/image_name
docker image push dockerhub.myprivateregistry.com/image_name
# Logging in to your private registry
docker login dockerhub.myprivateregistry.com
# Save an image to a file
docker save -o image.tar image-name:v1
# Load in saved image file
docker load -i image.tar
# Building an image from a dockerfile
docker build /path/to/dockerfile
# Building an image with a specific name
docker build -t <image-name> /path/to/dockerfile
Now it’s also worth touching on the rough structure of a Dockerfile
FROM <base-image-name>
RUN <any-valid-shell-commands>
COPY <src-path-on-host> <dest-path-on-image>
The main command words used here are:
FROM- Specifies the starting image.
RUN- Allows you to execute shell commands
- Can be efficient to chain them using
\for commands that span newlines and&&to connect the commands together.
COPY- Allows you to make create and move copies of files within your local file system into a location within your image/ end container.