Disclaimer: There has been a large amount of work performed by people when it comes to understanding of LLMs and the like. As a result this post isn’t made with the intentions to re-work the efforts of many but rather guide it’s exploration, focusing on some of the key, personally biased, interesting aspects. Also, at the end of the day ChatGPT is a proprietary model, meaning unless you work at OpenAI you don’t acutally know the specifics beyond the information that has been publically released or empirically evaluated. Always ensure you read multiple sources when trying to verify your own thoughts.
Table of Contents
- Resources to learn more
- Lets take a step back…
- How is it trained?
- Are all LLMs similar to ChatGPT based models?
- So what are the drawbacks?
- ChatGPT Plugins, how do they work?
- Underlying ChatGPT Model Architecture
- So what’s the future of ChatGPT?
Resources to learn more
Plenty of excellent resources exist within this space (far too many for me to exhaustively quote). Here I have links to a few that I have found particularly useful in my journey, in no particular order:
- Videos
- Andrej Karpathy excellent summary of GPT at Microsoft Build 2023
- Andrej Karpathy building GPT from scratch tutorial
- Neel Nanda Transformer walkthrough series
- Breaksdown how GPT esque (GPT-2 specifcally) transformers work under the hood, explainging a bunch of terms along the way.
- Nice short ChatGPT training summary
- Artcicles/ Blogs
- OpenAI ChatGPT blog post
- OpenAI forums, basic math ideas
- OpenAI text embeddings blog resources
- Medium post high level summary
- Bea’s highlevel GPT intuitions overview
- Jay Alammar GPT-2 Illustration
- Jay has plenty of other resources which are great,referencing this since it’s GPT article, feel free to explore others on his blog too!
- Stephen Wolfram explaination of ChatGPT
- Stephen is the creator of the Wolfram Alpha project which has the underlying aim to provide “deep computational abilities” in the form of a tool. As a result of his work he has unique views on ChatGPT & LLMs and is able to tie these into how it relates to his work.
- Decoder Transformers Text Generation process
- Huggingface blog post on different ways the probability sampling process works to yield text generation capabilies for transformers.
- ChatGPT based models most likely use similar sampling logic.
- Research Papers
- GPT background (university thesis)
- GPT-3 & 3.5 capabilitiy overview
- OpenAI GPT-4 technical report
- Microsoft research showcases sparks of general intelligence by GPT-4
- GPT-4 seems to show elements which form part of an AGI system, this is done in the context of the rubrik they define.
- Proximal Policy Optimization paper by OpenAI
- False Promise of imitating proprietory LLMs
- In short not all open source LLMs are as good as imitating proprietary models used in ChatGPT for instance as you may think, be skeptical and investigate thoroughly!
- Code Repos/ Notebooks
- OpenAI baselines
- ChatGPT prompt templates
- Scikit LLM
- Allows you to call OpenAI ChatGPT based LLM models along with others too.
- Follows similar API to standard
scikit-learnpackage.
- Implementing Generative AI Chatbot
- Heiko Hotz works at AWS as a Senior Solutions Architect & Generative AI advocate.
- Showcases how to use state of the art open source models to create ChatGPT like chatbots with pluggin like capabilities.
- Other
- Mechanistic Interpretability Gloassary
- Useful reference to recall jargon terms when trying to understand GPT based models.
- Would recommend the Transformers, Machine Learning and parts of Transformer Circuits as primary references.
- Transformer Evolution Summary
- Lucas Beyer (Google Brain) summary of the evolution of transformers.
- Great since it showcases how various areas of ML have been impacted by the transformer architecture and includes some high level maths too!
- Prompt Engineering Guide website
- Go to guide for prompt engineering, can act as a good one stop shop for understanding prompting (references a bunch of additional material).
- Contains details on ways to prompt a variety of different underlying models/ application types.
- Mechanistic Interpretability Gloassary
Lets take a step back…
“A revolutionary technology is one that has the potential to improve our lives in ways that we can’t even imagine.” - Elon Musk, CEO of Tesla and SpaceX
I think this captures really well the reasons why ChatGPT can itself be considered “revolutionary”. In my opinion, you can view it as one of the many pivotal shifts in technology made by humanity, not only due to it’s game changing capabilities impacting multiple industries but also based on the impact it’s had on peoples perception of AI moving into the future. I have added a pictorial representation of this below.
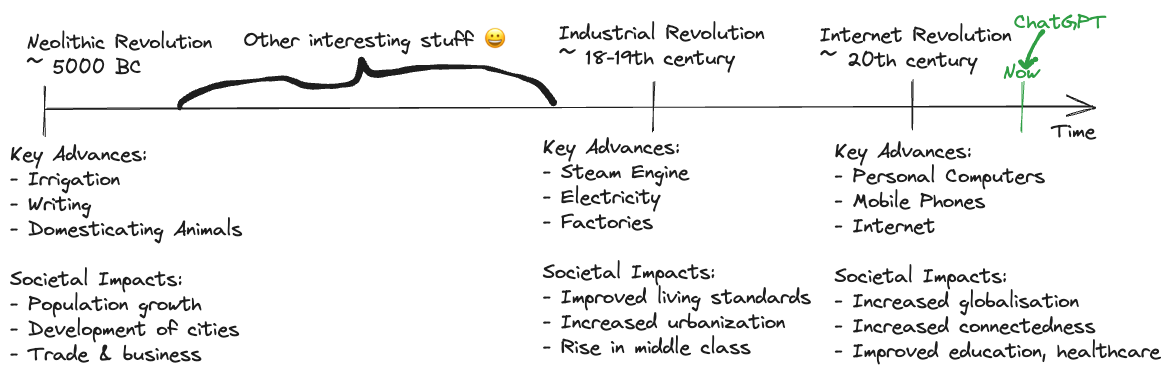
Many companies such as Microsoft, Google, Amazon & others have subsequently started taking big strides to capatilize on this rapid perception change, making massive multi-billionaire dollar investments, which they hope will pay off in the coming years. Bloomberg estimate the market cap for Generative AI to reach over $1 trilion by 2032 meaning ChatGPT would “just be the beginning” of what is to come.
How is it trained?
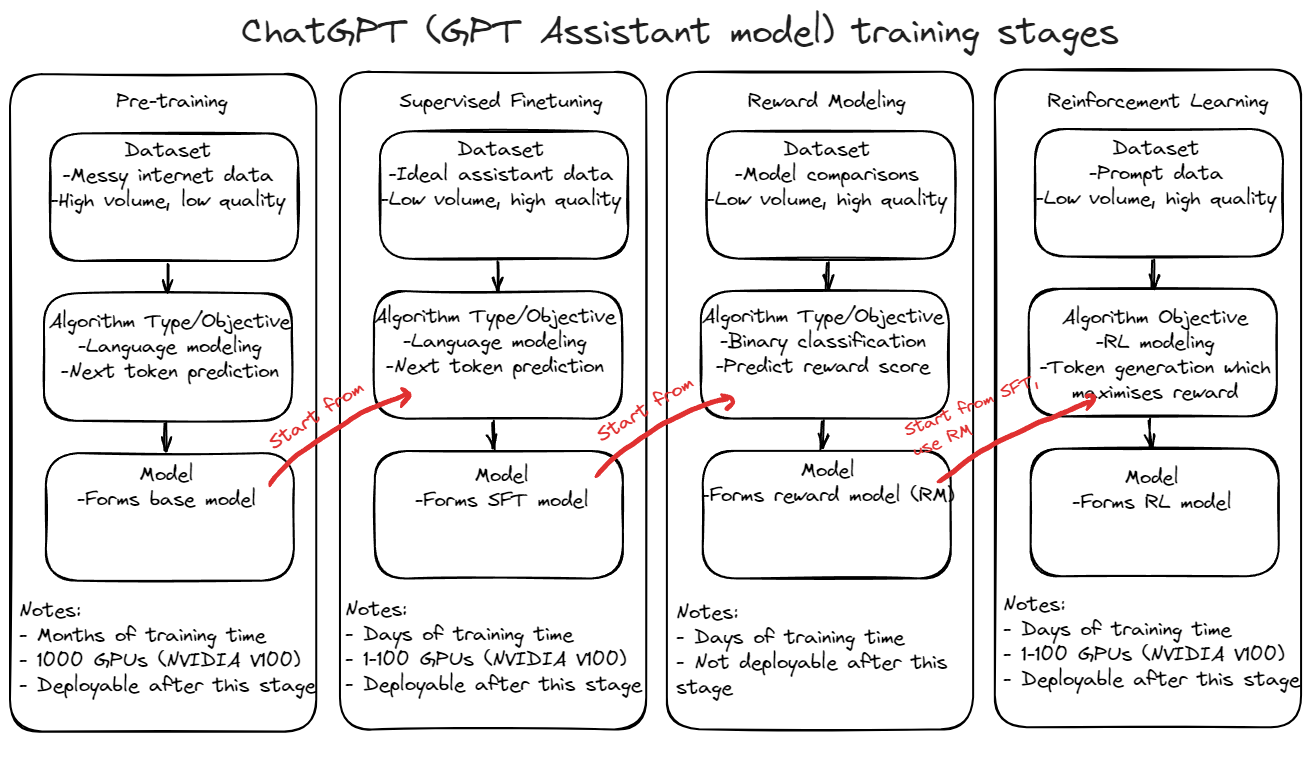
At it’s core it seems that there are 5 key steps to training GPT based models used in sequence:
- Pre-processing
- Getting things setup so subsequent training methods can take place
- Data collection
- Tokenization of text data
- Generating embeddings1
- Pretraining
- Majority of the time & compute power is spent here (months of training on 1000s GPUs)
- Large quantities of natural language data is consumed
- Underlying objective is to predict the next token
- Forms base model (relatively bad and not really useful)
- Supervised Finetuning
- Reward Modeling
- Binary classification problem
- Output of logit reward scores
- Reinforcement Learning
- Used to optimise text generation
The first pretraining stage can be thought of as a typical standard training stage while the subsequent three (SFT, RM & RL) are forms of finetuning performed ontop of the base model formed via the pre-training stage.
Let’s go into abit more depth on each one.
Preprocessing
Before you can feed your data into models you must make sure it’s of the right structure, something synonomous with ML modelling in general.
You can think of the underlying data as being text data, since neural networks cannot process this text data it first needs to be converted into numbers (or more precsily a list/ vector of numbers). It’s important to note that ultimately all characters that occur typically in text may need to be handled and so one possible way to do this is creating almost like a giant lookup table (vocab dictionary) of typical characters along with a unique numerical representation. This overarching process is known as tokenization and the name given to each individual item of text that is converted is a token. A possible algorithm for this is Byte Pair Encoding which seems to be widley used but others exist as well. After this the tokenized text is then converted into a vector representation otherwise known as an embedding.
Note: Byte-Pair encoding is essentially like starting with each of the $256$ $\text{ASCII}$ characters in a dictionary (as your base vocab). You then precede through your corpus of text and then ask the question “which pairs of characters are most likely to occur next to each other based on the count frequency within your corpus of text” and for those you merge the respective $\text{ASCII}$ tokens and add the resulting merged token to the vocab dictionary you are maintaining. You procede to do this for the entire text up until you reach your desired fixed vocab size (each iteration through the text merges and adds that merged result to your dictionary, so the more iterations performed the more entries will form in your dictionary). Usually tokenizers exist already which have performed this activity for you on a standardised corpus of text, you may just leverage them and use them to then tokenize any subsequent text (effectively looking up and seeing if that text can be broken down by values present in your dictionary).
Pre-training
Now begins the fun part, training, so with the data in the right format we just need to feed this into the underlying model. To do this we can structure our various corpuses of text data into $2\text{D}$ array like strucutres of the shape $\left(\text{B}, \text{T} \right)$ where $\text{B}$ represents the batch size (number of text documents we have) and $\text{T}$ represents the context length (length of each document or the number of tokens in a document).
Note: Special end of text tokens are used to delimit the various documents from each other. This way the model can inherently learn based of the various source data that is fed into it.
Now the model architecture used by the GPT models is Transformer neural network architecture which leverages the attention mechanism which is different way of allowing the model to attain & retain context on each individual token as it’s passed through the network. This plays a keyrole when it comes to understanding the next point.
Each of the batches is then fed into the nextwork one by one where each token within that particular batch can be thought of as being the center of attention where given all tokens to it’s left along with itself, the subsequent token is then predicted. This process is then replicated in parallel for each token within the context length of that batch . This is then repeated for each of the batches with the the negative log likelihood being optimized on typically, Remember we have acess to the actual tokens during training so it is technically supervised in that sense.
During this phase you can think of the distribution from which the tokens are being sampled from for each prediction as being tweaked and this learning process being translated through in some form or another to the $175\text{B}$ (GPT-3 size) or so parameters. Therefore the lower the loss as measured on the validation set can be thought of as the model giving a higher probability to the choosen token that it is predicting (picking the best next integer in the sequence ie best word/text).
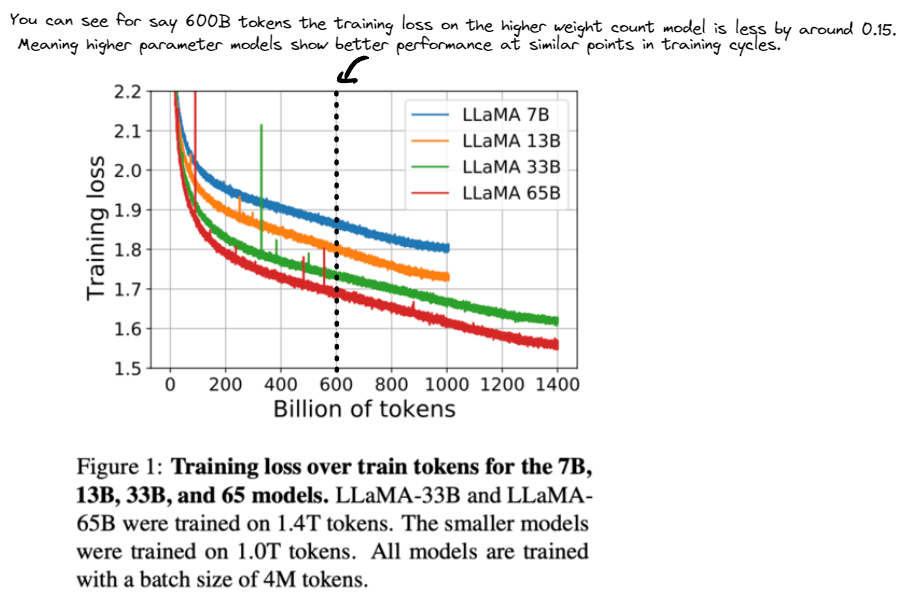
After this you can think of the main base language model having been formed. You can imagine that in the case of GPT based models having been trainined on billions/trillions of input tokens it would have learn’t some fairly powerful general purpose representations of natural language which can then be finetuned for various use cases downstream.
Note: Early forms of this kind of learning were made by Aristotle, supposedly one of the first people to discover that the semantic meaning of things depicted using natural language could be abstracted and generalised across conversations. This lasted then for awhile until George Bool created the foundations of formal logic allowing for the further abstraction away from language strucutures and into symbolic reasoning.
It’s important to note that at the model wouldn’t be that user friendly just yet (not an assistant just yet) but utlimately you could in theory still “trick the model” to perform tasks by arranging your input document in such a way to allow for it’s continuation natually. This would provide the best chance of you getting a response while staying within the bounds of what the model has been trained for thus far (next token prediction). One way of doing this is by few-shot prompting where you tweak the input prompt to be in the form of a dialogue (say between a human and assitant) and end it in a way which leaves it open to continuation.
Supervised Finetuning
This is where the real magic begins….
To start you need to collect a decent amount (order of magnitude around $100\text{K}$) of high quality labelled data containing input prompt and ideal response pairs. This process can be performed by contractors say through Amazon Mechnanical Turk.
With this in place you can perform the same language modelling task (next token prediction) on this dataset.
Note: This process can be thought of as showcasing & allowing the model to learn how humans respond to questions. Kind of like if you had a child and they know the basic vocabulary from home schooling (pre-training in our case) and then you send them to nursery to “fine-tune” how they should use that vocabulary in practice. It’s important to note that the contractors forming the response would have had detailed labeling instructions that they follow when creating the ideal responses. Kind of like how inadvertenyl teachers in a classroom who children interact with would have been predisposed to the strucuture of communications.
This is great however there is still some drawbacks when it comes to alignment which is what the next steps deal with.
Reward Modelling
Here various potential responses are gathered from the SFT models output given the same input. These can be thought of as multiple completions that the model has created which can then be ranked by people. If we let $\text{n}$ equal the number of completions per prompt then there are $\binom{n}{2}$ possible combinations served to the reward model as a batch training datapoints (since this is the number of ways to perform pairwise rankings of $n$ items & serving each separate datapoint led to overfitting issues). This step can take awhile since alot of completions can be difficult to objectively compare & you’ll also want to ensure you have sufficient examples ($100\text{K}$-$1\text{MM}$)
Note: You may have seen the option to give a 👍 or 👎 to responses on ChatGPT, Bard or other LLM based apps. This is just helping with this data collection part of the reward modelling process.
Using this ranked data a reward score can be predicted by our model for each of the completions provided for a given prompt. The loss function that the model is optimised for is one which captures a measure of the predicted rewards consistency when compared with the labeled ordering provided by the ranked labels.
Note: You can think of the loss function enforcing the model to align in such a way that provides higher scores to completions that are favoured by humans (as per the ranking preference present within the dataset) and lower scores to the others.
This activity alone isn’t that useful and isn’t something that you can deploy straight away. Instead it works itself nicely for the next stage.
Reinforement Learning
Now with the reward modeling part complete this model is then fixed meaning we can append and score arbitrary completions with this model.
Another similar, albeit smaller, sample of data to the step before is collected (around $10$-$100\text{K}$). This can then be used to perform RL with respects to the reward model whereby you take batches of prompts and there respective completions which can now be scored by the fixed reward model which provides a reward score for each completion.
The objective loss function still remains similiar to prior steps just with an added weighting according to the reward score for that completetion. E.g say a completion had a high positive reward score, this would mean the associated tokens in that completion would be “reinfored” by the RL agent and other lower scoring completions would have the opposite effect. This process is repeated across many batches (prompts,completions) forming your policy $\pi\left( \text{a}\mid \text{s}; \theta \right)$ (mapping from states to actions) which then allows you to create completions following this policy (which has been optimized by the agent to favor things according to the reward model).
Note: The actual policy is a stochastic policy rather than deterministic policy as you don’t want the same output for a given prompt but instead a variety. Ultimately the “temperature” parameter, which you can tweak, allows you to alter the sampling performed by the policy to favour less probable tokens. This doesn’t actually changing the policy itself but rather controls what the policies outputs. Perhaps2 mathematically something like $\pi\left( \text{a}\mid \text{s}; \text{t} \right) = \frac{ \text{exp}\left(\text{Q}(\text{s},\text{a}) \cdot \text{t}\right)}{\sum_{a} \text{exp}\left(\text{Q}(\text{s},\text{a}) \cdot \text{t}\right)}$ represents the policy with temperature $\text{t}$ and $\text{Q}\left(\text{s}, \text{a}\right)$ is the expected reward function. The temperature parameter can scale the values of the reward function which can lead to a few different results. A low value means the reward function will be scaled down hence the policy is more likely to choose actions that have a high probability and vice versa.
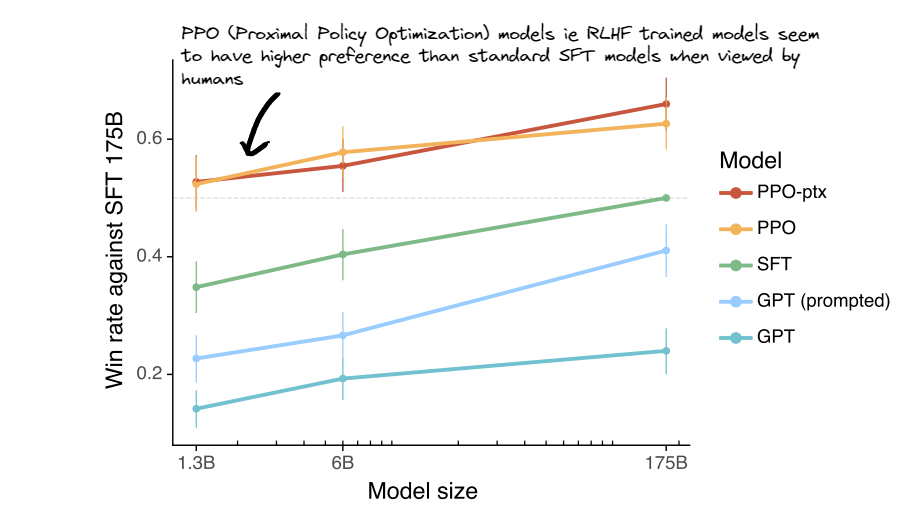
The previous two steps are ultimately form the Reinforcement Learning from Human Feedback pipeline.
It’s interesting to note at this point that the RLHF stage isn’t required to get output out however as shown in the image below it can yield more useful output.
Are all LLMs similar to ChatGPT based models?
The short answer is No! Alot of the other models will most likely use a similar overarching transformer based architecture but most likely would be using different data for training & might not be RLHF but instead only pre-trained base models or upto SFT stage. The key is always reading the documentation that comes with a model to understand what methodology was used and if it aligns with what you want.
So what are the drawbacks?
Well for starters ChatGPT isn’t always factually correct & often can halluncinate even though it’s factual knowledge base far exceeds that of any single human (it’s been trained on more text then any single human has typically seen). When understanding why this could be it’s important to understand that it isn’t just performing some sort of fancy database retrieval (which in theory would mean it could just “lookup the right answer”) but rather learning some internal representation of the data during training which it then uses to recurisvely generate text via sampling from a probability distribution.
- One possible argument is since the actual data it’s trained on contains fictonal and factual information when it comes to generating new text it could leverage it’s learnings from fictional data.
- This could be be exacerbated by the ambiguity in the question you are asking as the model would rely heavily on it’s own internal learned represesentation to help guide it’s .
- E.g Say your question is “What are the effects of time travel?” this can be interpreted in different ways by the model, you could indeed be looking for a “factual explanation” of this hypothetical scenario based of current scientific theories or instead looking for some sort of fictional description based of an anime, such as Steins;Gate, which it may have heard of through some Reddit conversation it saw during the pre-training stage or something else…. The issue is the model doesn’t have a definitive way to know and may lean on it’s local context.
This factual inconsistentcy can lead to real problems since it can be very difficult to spot when it is occuring as the model is good at “sounding right”. As a consequence it’s always important to check over outputs, especially when you desire factually correct responses.
ChatGPT Plugins, how do they work?
For those poeple who decide to pay the premium subscription fee for ChatGPT Plus you’ll also be able to access plugins. These are essentially 3rd party connectors which allow you to access useful external services via the ChatGPT application. Good examples of these services include Wolfram (deep computation abilities), Search (browsing the web for information) and many others.
An interesting question arises in how these applications are able to communicate with the underlying models. A flow diagram has been added below to help demonstrate this but the key concept is the idea of an agent which is able to act on behalf of the model and route information “to & from” the external serivces and provide the responses in a way consumable by the underlying LLM.

Underlying ChatGPT Model Architecture
As mentioned before ChatGPT is an application which makes use of LLMs under the hood. In particular these language models are GPT (or Generative Pre-Trained Transformer) meaning that they based on the transformer architecture (first released to address language translation problems in Googles highly cited 2017 paper) but adapted accordingly after showing promise in various other domains.
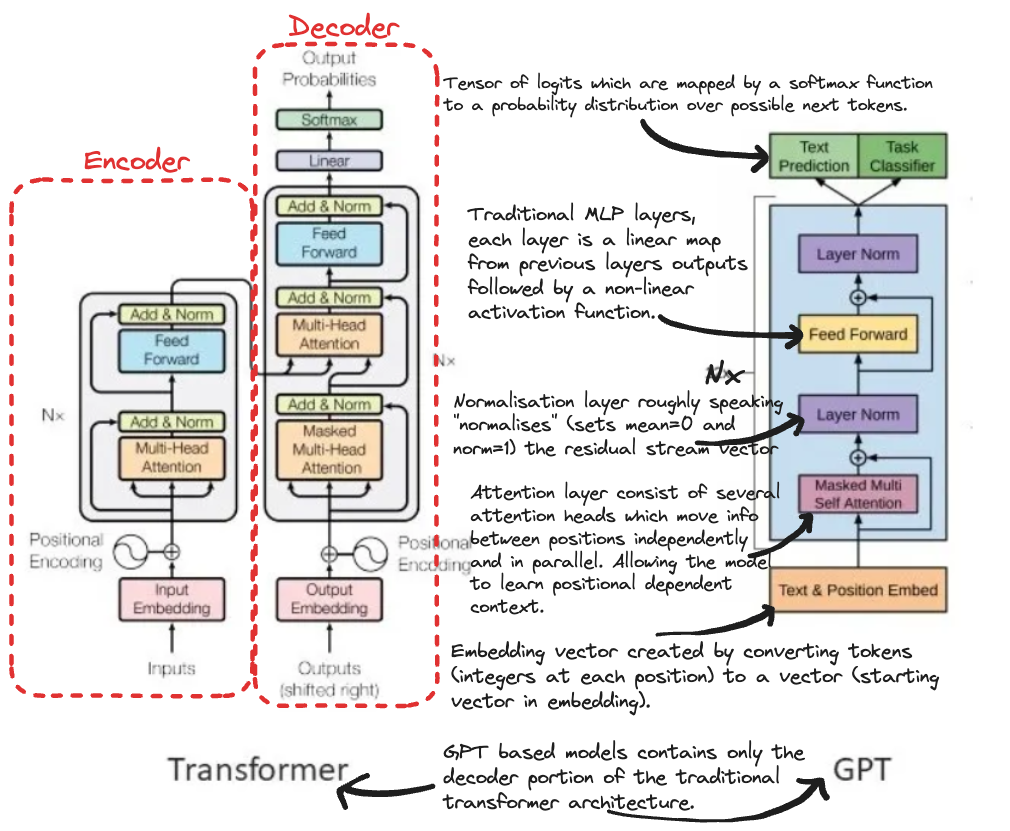
It’s important to note that this diagram is somewhat “fuzzy” at best and doesn’t do justice to the the more formal mathematical underpins for which I will divulge to the brilliant A Mathematical Framework for Transformer Circuits paper produced by Neel and other researchers at Anthropic.
It provides a great way to formally represent the mathematics of the GPT based transformer aswell as terminology which you can adopt to standardise things (e.g notion of Residual Stream present in my annotated diagram is based on their defintion).
An alternative (yet related) view is from the perspective of a software engineer (more programming heavy) which can be found in Nelsons Transformers for Software Engineers post. For a more complete understanding I recommend going over both.
So what’s the future of ChatGPT?
Here is a cool diagram showcasing the wider development up until now in the LLM space.
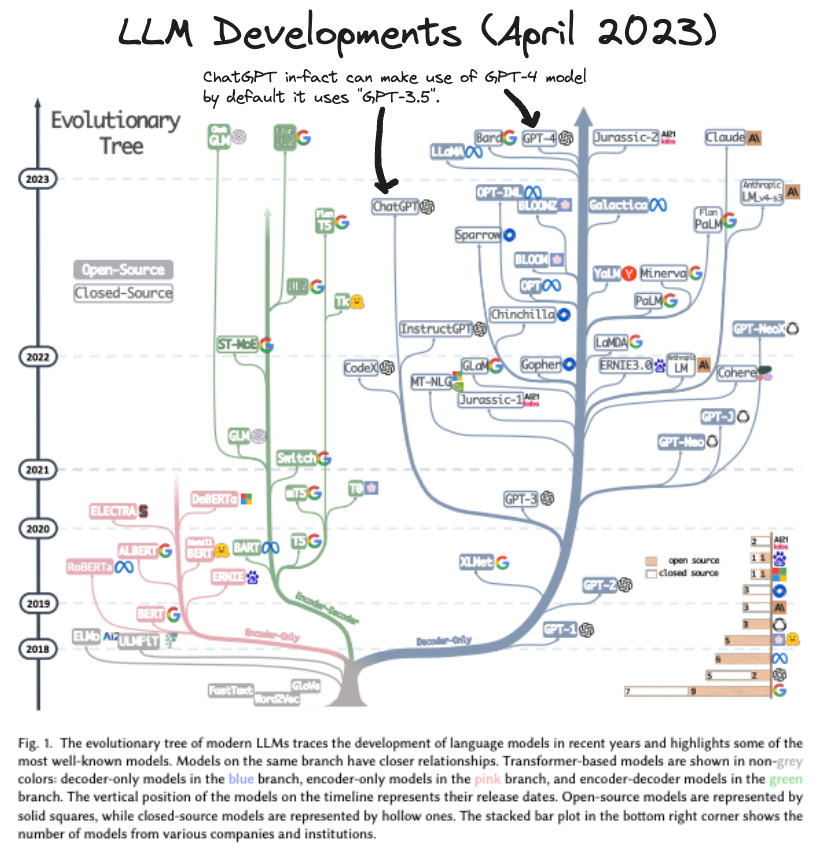
As you can see ChatGPT is just a small portion of this ever growing tree and most likely we’ll see a bunch of new branches in the coming years with the increase in open source capabilities.
Ultimately there are a number of ways things could pan out and, in my opinion, could well be a computationally irreducible problem. A testament to this is if you asked anyone say 10 years or so ago “how would AI effect jobs in the future?” most people would have told you AI would take over jobs in roughly the following order Blue-Collar (factory workers) –> White-Collar (office workers) –> High IQ jobs (engineering, quant finance, etc) –> Creative jobs (creative writers, artists etc) however things have panned out in almost the opposite direction (shows the fine line that exists when trying to predict developments).
Having said that to avoid dodging the question some of the key things Sam Altman has hinted at are:
- General improved efficiencies of underlying models.
- Potential algorithmic improvements in LLMs and their abilities to perform language tasks.
- This is interesting as some fear we are reaching the limits of compute but by tweaking things such as high quality datasets, underlying algorithmns, compute requirements etc there is still room to grow stronger and better models.
- Further integration into existing applications via plugins.
- ChatGPT has already got some plugins that you can use but you can imagine this number only increasing as time goes on.
- Further plugins would yield ever more utility allowing people to perform an increasing number of tasks through the single ChatGPT interface.
- New research avenues which focus on more accurate knowledge generation.
- Write now a fundamental issue with ChatGPT is that the LLMs are designed to generate most probable text without a larger objective more closely aligned with generating “new knowledge”.
- This very well may require a few more breakthroughs but could be something that is integrated in as part of a future model which the ChatGPT application can access too.