Table of Contents
- Introduction to Active Learning
- Basic Terminology
- Common Query Scenario’s
- Key Query Strategies in Active Learning
- Resources
Introduction to Active Learning
When performing supervised machine learning it’s common to face the challenge of not having enough labelled data. This could be for a variety of reasons some being controllable others not. In the scenario where things are in your control for instances when labelling sentiment (neg, neu, pos) for a large dataset it would be nice to a access to a suite of techniques which could enable you to handle this, this is where active learning comes in.
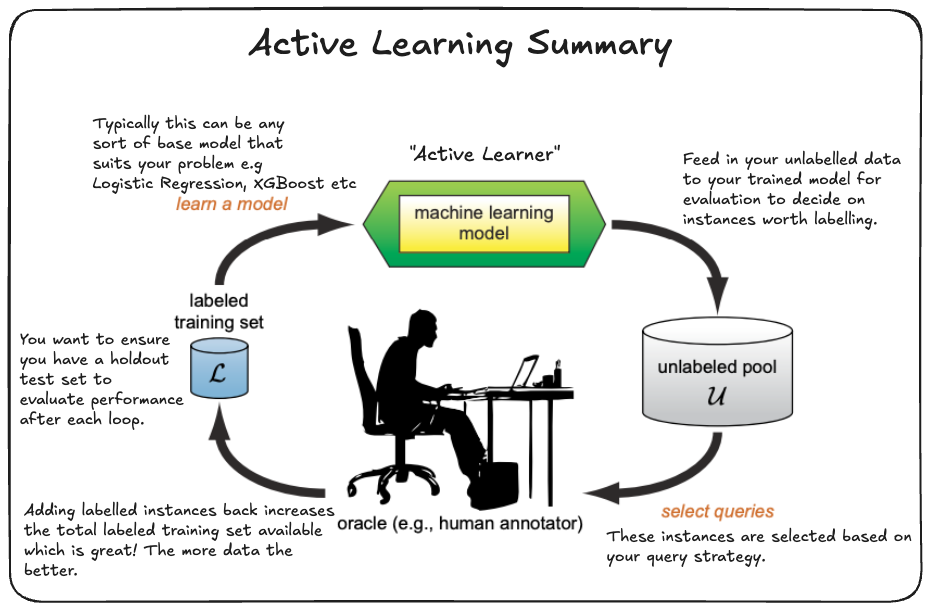
Active Learning is a machine learning paradigm where an algorithm defines the process by which you want to go about performing labelling on a set of partially labelled data in a way that maximizes effeciency. This allows you to increase the total amount of labeled data you have to train your model on allowing you to focus on what’s important (building the best model) rather than worry about the lack of labeled data inhibiting. The more traditional approach of just using all your labelled data (if it’s not too large) or taking a sample from it (if it’s too large) and training a model on it is sometimes referred to as Passive Learning.
This approach can come in handy particularly when labeling data is expensive or time-consuming.
Basic Terminology
- Instance/Sample
- A single data point within your dataset. For example if your dataset is a table then it’d be a single row (more formally object/entity) of desire.
- Learner/Active Learner
- This represents the algorithm which defines your active learning how your process is going to go about labelling your data.
- Sometimes people also refer to the underlying ML base model combined with the choosen active learning algo with the same name so just be prepared.
- Oracle
- The entity who can perform the labelling of the instances/samples choosen by the active learner model, typically humans.
- Based on the notion of an Oracle in ancient greece refering to a wise person.
- Query Instances/ Queries
- These are the instances/samples that your learner has picked out as being the informative one as per the query strategy choosen as part of your active learning process.
- Query Scenarios/ Method
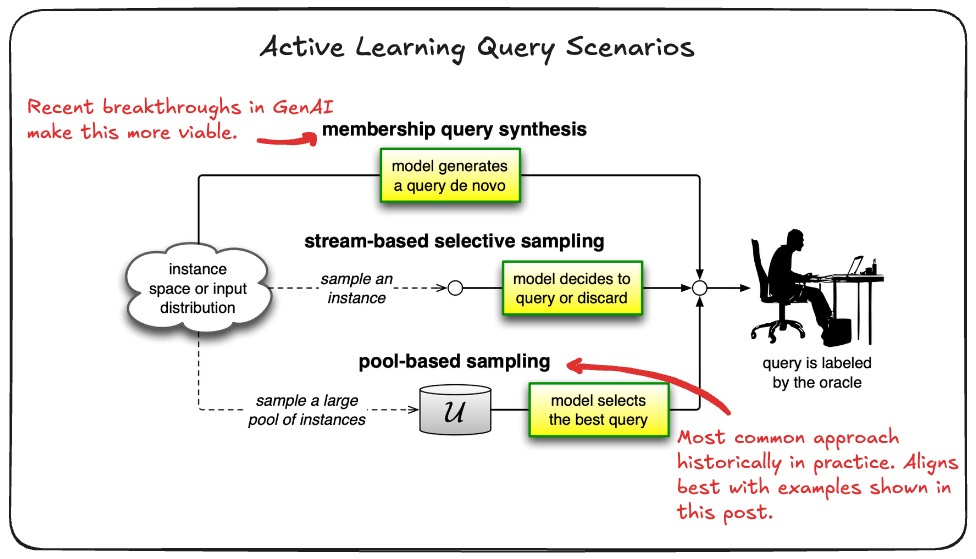
- These the common situations upon which we find active learning models requesting an oracle to query an insance under. These were defined at an academic level and provide ‘a way’ of thinking about the use cases.
- Tend to fall into 3 buckets:
- Membership Query Synthesis: When the learner generates/constructs an instance (from some underlying natural distribution). For example, if the data is pictures of digits, the learner would create an image that is similar to a digit (it might be rotated or some piece of the digit excluded) and this created image is sent to the oracle to label.
- Stream-Based Selective Sampling: in this setting, you make the assumption that getting an unlabelled instance is free. Based on this assumption, you then select each unlabelled instance one at a time and allow the learner to determine whether it wants to query the label of the instance or reject it based on its informativeness. To determine informativeness of the the instance, you use a query strategy (see next section). Following with the example above, you would select one image from the set of unlabelled images, determine whether it needs to be labelled or discarded, and then repeat with the next imagine.
- Pool-Based sampling: this setting assumes that there is a large pool of unlabelled data, as with the stream-based selective sampling. Instances are then drawn from the pool according to some informativeness measure. This measure is applied to all instances in the pool (or some subset if the pool is very large) and then the most informative instance(s) are selected. This is the most common scenario in the active learning community. Continuing with the example in the above two scenarios, all the unlabelled images of digits will be ranked and then the best (most informative) instance(s) will be selected and their labels requested.
- Query Strategies
- This refers to the way in which the learner goes about judging whether an instance/sample of your data is informative or not.
- Various query strategies exist but commonly fall into the following buckets:
- Uncertainty Sampling: The model queries the data points for which it is least confident in its predictions.
- Query by Committee: Multiple models (a committee) are trained, and the data points on which the models disagree the most are selected for labeling.
- Expected Model Change: The model selects data points that would result in the greatest change to the current model if labeled and added to the training set.
Common Query Scenario’s
Key Query Strategies in Active Learning
As laid out in the definitions a number of different classes exist for discriminating between informative and non-informative samples/instances. Here the focus will be on the Uncertainty Sampling based class due to it being one of the more popular classes and easier to discuss in the context of a traditional classification problem. That being said a resources have been provided which expand on the other techniques in more detail.
Uncertainty Sampling
Here are the main uncertainty sampling techniques. Each method represents a different approach to measuring uncertainty.
Least Confidence Sampling
Least Confidence sampling focuses on the highest probability.
import numpy as np
def least_confidence_sampling_binary(model, unlabeled_data, n_samples=1):
predictions = model.predict_proba(unlabeled_data)[:, 1]
uncertainties = np.abs(predictions - 0.5)
return np.argsort(uncertainties)[:n_samples]
def least_confidence_sampling_multiclass(model, unlabeled_data, n_samples=1):
predictions = model.predict_proba(unlabeled_data)
uncertainties = 1 - np.max(predictions, axis=1)
return np.argsort(uncertainties)[-n_samples:]
Margin Sampling
Margin Sampling looks at the difference between top two class probabilities.
import numpy as np
def margin_sampling(model, unlabeled_data, n_samples=1):
predictions = model.predict_proba(unlabeled_data)
sorted_predictions = np.sort(predictions, axis=1)
margins = sorted_predictions[:, -1] - sorted_predictions[:, -2]
return np.argsort(margins)[:n_samples]
Entropy Sampling
Entropy Sampling considers the entire probability distribution across all classes.
import numpy as np
def entropy_sampling(model, unlabeled_data, n_samples=1):
predictions = model.predict_proba(unlabeled_data)
entropies = -np.sum(predictions * np.log(predictions + 1e-10), axis=1)
return np.argsort(entropies)[-n_samples:]
Query by Committee
Multiple models (a committee) are trained, and the data points on which the models disagree the most are selected for labeling.
# Query by Committee
def query_by_committee(models, unlabeled_data, n_samples=5):
predictions = np.array([model.predict(unlabeled_data) for model in models])
disagreement = np.var(predictions, axis=0)
return np.argsort(disagreement)[-n_samples:]
Expected Model Change
The model selects data points that would result in the greatest change to the current model if labeled and added to the training set.
# Expected Model Change
def expected_model_change(model, unlabeled_data, n_samples=5):
gradients = []
for x in unlabeled_data:
grad = model.compute_gradients(x)
gradients.append(np.linalg.norm(grad))
return np.argsort(gradients)[-n_samples:]
Resources
- Active Learning by Burr Settles
- A well known technical report providing a survey of the Active Learning space.
- Good for understanding the theory behind things but not for those pragmatically inclined.
- modAL
- A python framework for performing active learning, a good pragmatic way to get a feel for the techniques.
- Not actively maintained, see github, likely not best to use for production without careful considation.
- Active Learning tutorial